...
| Expand | ||
|---|---|---|
| ||
 |
Prototype implementation
...
Checkout all the branches
edx-platform: msingh/oep37/mvp/userenrollments
ecommerce: diana/test-data-prototype
devstack: msingh/oep37/mvp/interface
start a virtual env and run
make requirementsin devstack reporun
make dev.load_data data_spec_top_ path=test_data/data_spec_top.yamlfrom devstack repoyou should now have new data in your database
if something went wrong, here are individual commands to run in each of the container’s shells
...
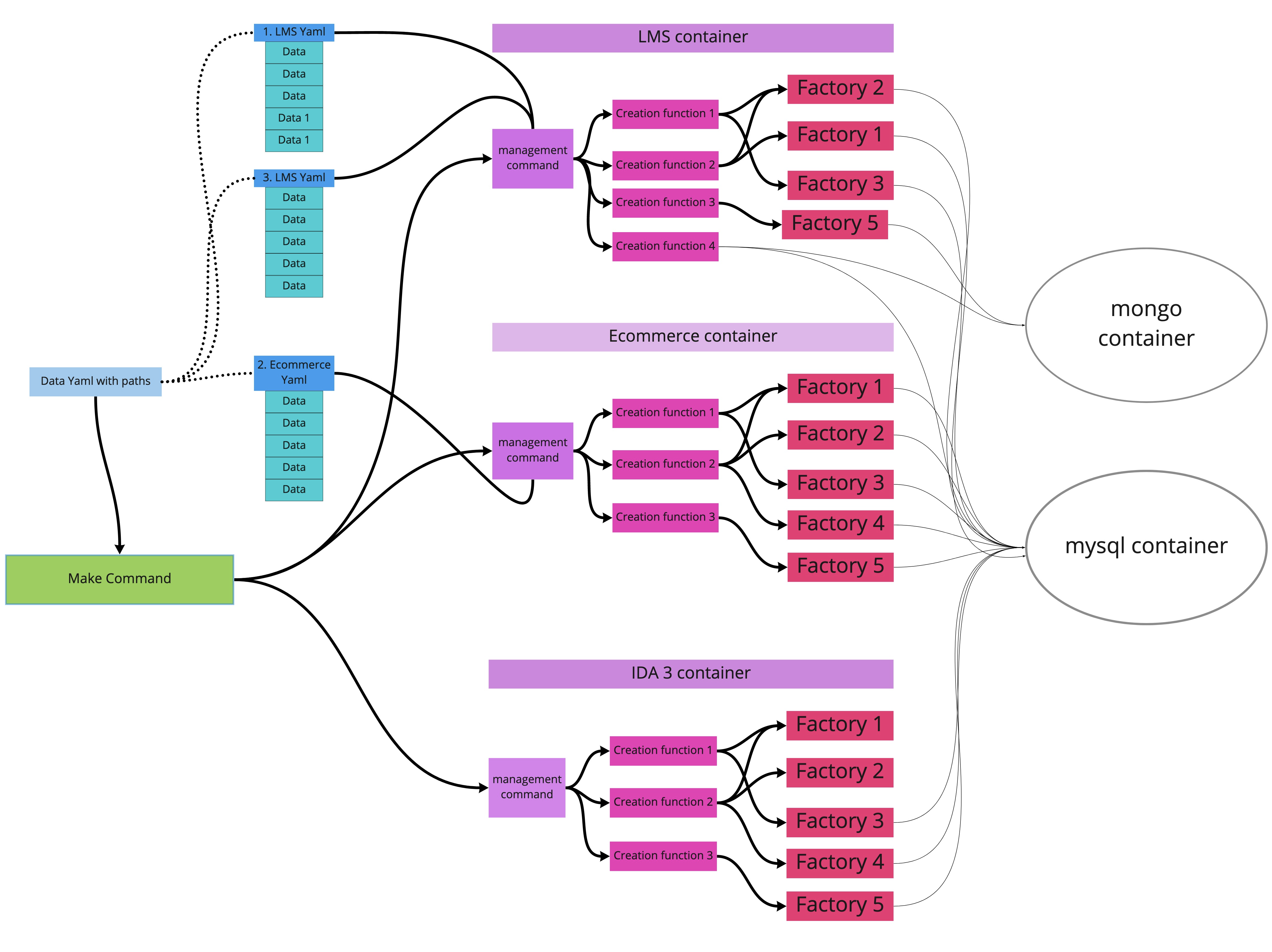
Data will be specified in multiple Yaml files
A top level yaml file will list other yaml files
The order by which the data is built in specific IDA will be specified in the top level yaml file
The data contained within the yaml files will be as minimal as possible
foreign keys will be linked via some unique identifier for lookup (i.e. course_key, domain, username)
For each use of the
load_testdev_datamanagement command, there will be a separate yaml file with data specified.The management command will read the specified yaml file and pass on the data specification to the appropriate data generation function.
We will be reusing existing factories used for unit tests
Benefits of reuse
Decrease in code duplication
There are ton of factories, so we’d be able to support ton of data creation very quickly
Downsides
There are ton of factories which were designed for different use cases. Due to the complex nature of some of these factories, it might be hard determine side effects on the database.
...