VEDA Ops
Architecture
For the overview of VEDA, go to edx-video-pipeline (VEDA). That has some nice architecture diagram as well

Get Started:
- Reach out in the Slack #video-pipeline and ask for a superuser to add you to the users list for Veda Admin
- Make sure you have your SSH key generated
- DevOps has fine documentation for you to setup your presence on edx-hub AWS account. Please follow it to setup your aws-hub account
- Access to the veda-secure repo. If you don't have access to the repo, ask to join the group at https://github.com/orgs/edx-ops/teams/veda-secure-contributors
- Then create a PR like https://github.com/edx-ops/veda-secure/pull/9/files to add your own ssh public key
- Create a PR like https://github.com/edx/edx-iam/pull/256 in the edx-iam repo. This will get you the permission to switch to veda role in AWS
- Terraform installed.
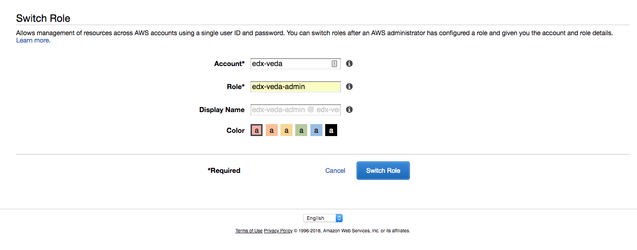
- Log into your aws hub account, if you haven't already, then switch your role to edx-veda-admin. See screenshot below. Then you should be able to see all VEDA EC2 instances! (Note: If you don't see any instances, make sure that you are looking at the U.S. East (N. Virginia) region. This is selectable from a pull-down menu near the upper right corner of the console.)
- Check out Flower for our queues as well
8. Go to EC2 service console, and go to the Key Pairs section, create your own security key pair associated with your edx-veda IAM role account.
Links:
Upload Tool: https://veda.edx.org/upload
(For uploading course marketing videos only)
CAT tool: https://veda.edx.org/cat
(For associating courses and youtube channels, as well as generating studio video_upload keys)
Flower: http://veda.edx.org:5555
(Celery Monitoring)
VEDA Django Admin: https://veda.edx.org/admin
Pipeline Repo: https://github.com/edx/edx-video-pipeline
Worker Repo: https://github.com/edx/edx-video-worker
Contents:
This document is broken down into several parts:
Basic operations
VEDA undertakes three basic operations.
I. Ingest:
- Files are copied from their source (typically the ed-studio set upload bucket).
- The metadata of the file is catalogued
- The file is copied to a long-term storage bucket
- The encode jobs are enqueued.
II. Encode
- Source video files are copied onto an encode worker and encoded
- The delivery job is enqueued
III. Delivery
- Encoded files are tested and routed to their endpoint (AWS S3, Youtube)
- The URL is tested and sent to VAL
- Youtube IDs are called back via an API a separate process
Access/Administration
Access to VEDA django admin is currently the purview of four superusers.
New users should be added at 'staff' level of access, and not be allowed to delete records. A user audit should occur twice a year to deactivate (not delete) out-of-date users.
| Superusers |
|---|
| Greg Martin (Deactivated) |
Access for ssh/AWS users is handled by devops, and should be limited to superusers and engineers actively working on the service.
Troubleshooting
Runsheets:
the VEDA SLA is currently 24 hours. After 24 hours, the following commonplace problems can occur:
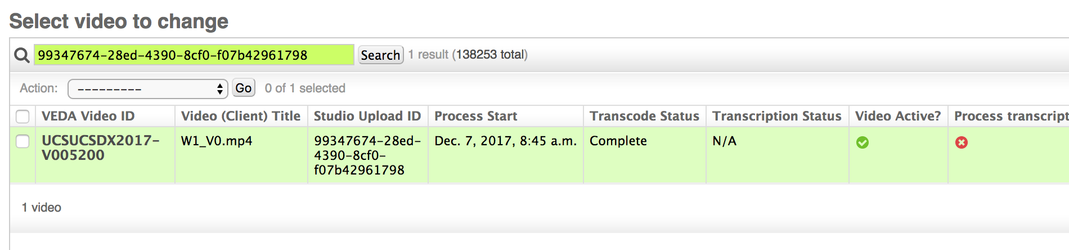
I. "A single video isn't completing"
Log into VEDA django admin. Search the provided studio ID, and it should correspond to a VEDA generated ID that's human parsable:
.png?version=1&modificationDate=1512749108087&cacheVersion=1&api=v2)
There is no VEDA record corresponding to the Studio generated ID:
The video upload has failed, and the course team must reupload the video
The VEDA status is "Complete", but not showing "READY" in Studio:
If this is an isolated incident, the video will show "READY" in studio the next time the 24 hour maintenance process ("HEAL") runs.
If the VEDA status is "In Progress" or "Active Transcode":
There is a missing encode. If the video "Process Start" field is more than 24 hours old, then the encode has been reattempted and failed. This indicates a problem with a specific encode and/or video, and generally not a systemic problem.
Search the URL table for records corresponding to the VEDA generated ID (e.g. "UCSUCSDX2017-V005200")
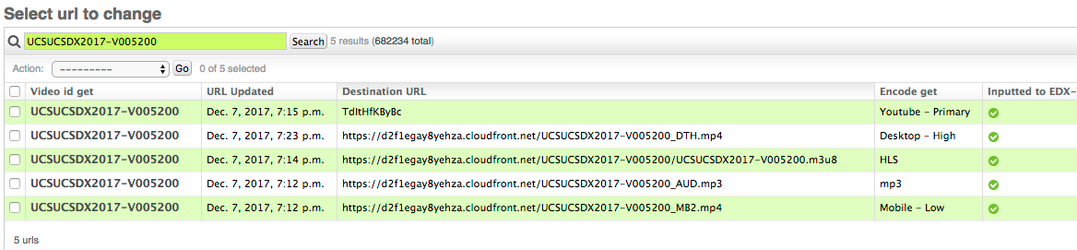
A complete file should show five encodes if the course is youtube enabled, or four if not.
If there are 0 encodes or only an HLS encode, then the video file may be corrupt, or the read metadata might be jumbled. (QA for HLS is less precise than for static files)
Reading the delivery node log might provide some context, and reading the encode node logs might provide some as well.
MOST COMMON: If youtube is the only encode missing, then an issue exists with the youtube version of the file. If the file hasn't shown up as a "youtube duplicate", then reading of the youtube logs might be appropriate to glean further knowledge. It's possible that the file is a duplicate, but the status is not catching.
II. "My whole course isn't completed"
Find an ID associated with this course using the steps above and check to see if the file is uploaded and has a few successful encodes. Most likely, the youtube setup is either incomplete (A bad CMS pairing) or misconfigured. If the CMS is paired wrong, a member of the author support team can resolve the issue, and if the youtube setup is misconfigured, it can be fixed in the Course record in VEDA django admin.
Reprocess the course once the issue is resolved via HEAL.
III. "Nothing is completing"
Most likely a service is broken and hasn't paged.
VEDA admin can provide some context.
- If there are no youtube IDs, then youtube_callback is most likely broken.
- If no new videos have come in, then ingest is likely the issue.
- If there are no encodes at all, then delivery is broken
Ingest and Youtube callback are the most fragile, so check them first (they both live on the same node, so it's relatively easy). The logs on each machine can provide some context, as a recent code change might be breaking something.
Alerting:
NewRelic
New relic records are available via the 'veda_production' app on the edX newrelic site. There are currently no push alerts set up.
https://rpm.newrelic.com/accounts/88178/applications/32434455
Splunk (Pending)
Splunk will be enabled (and will supplant the logging procedures below) once the Ansible work undertaken by Mallow lands
Email Alerts
An email alert is sent out via AWS SES if a process crashes. This is sent to the list at veda-dev@edx.org
HEAL:
Once a day, at 0:00 Eastern, a process runs via Celery ETA that attempts to re-run failed encodes for all videos with an ingest time within the last 6 days.
This process also resends data to VAL, updating statuses.
If a specific course or video ID needs to be reprocessed, a superuser can run a script to specifically run an ID or IDs through the process, checking for missing encodes and requeueing them. This is useful when resolving a localized issue for a course team for a video or course, especially if the course has videos that are older than six days.
Access the delivery node and from the bash prompt run:
To heal a single ID:
DJANGO_SETTINGS_MODULE='VEDA.settings.production' edx-video-pipeline/bin/heal -i ${VEDA_VIDEO_ID} # e.g. "UCSUCSDX2017-V005200"
To heal an entire course:
DJANGO_SETTINGS_MODULE='VEDA.settings.production' edx-video-pipeline/bin/heal -c ${VEDA_INSTITUTION_ID}${VEDA_COURSE_ID} # e.g. "UCSUCSDX"
Re-ingesting a failed video
Sometimes, when a video fails in ingest, it's necessary to make the HTTP request again. This is usually necessary if a video hasn't fully ingested, and isn't copied over to hotstore yet, so you can't run heal on it.
In any python shell, run this, replacing "FILL_IN_STUDIO_UPLOAD_ID_HERE" with the studio upload ID of the video.
>>> import requests
>>> data = '{"Type" : "Notification","MessageId" : "22b80b92-fdea-4c2c-8f9d-bdfb0c7bf324","TopicArn" : "arn:aws:sns:us-west-2:123456789012:MyTopic","Subject" : "My First Message","Message" : "{\\"Records\\":[{\\"s3\\":{\\"object\\":{\\"key\\":\\"prod-edx/unprocessed/FILL_IN_STUDIO_UPLOAD_ID_HERE\\"}}}]}","Timestamp" : "2012-05-02T00:54:06.655Z","SignatureVersion" : "1","Signature" : "EXAMPLEw6JRNwm1LFQL4ICB0bnXrdB8ClRMTQFGBqwLpGbM78tJ4etTwC5zU7O3tS6tGpey3ejedNdOJ+1fkIp9F2/LmNVKb5aFlYq+9rk9ZiPph5YlLmWsDcyC5T+Sy9/umic5S0UQc2PEtgdpVBahwNOdMW4JPwk0kAJJztnc=","SigningCertURL" : "https://sns.us-west-2.amazonaws.com/SimpleNotificationService-f3ecfb7224c7233fe7bb5f59f96de52f.pem","UnsubscribeURL" : "https://sns.us-west-2.amazonaws.com/?Action=Unsubscribe&SubscriptionArn=arn:aws:sns:us-west-2:123456789012:MyTopic:c9135db0-26c4-47ec-8998-413945fb5a96"}'
>>> headers = {'Connection': 'Keep-Alive', 'Content-Type': 'text/plain; charset=UTF-8', 'x-amz-sns-message-type': 'Notification'}
>>> url = 'https://veda.edx.org/api/ingest_from_s3/'
>>> r = requests.post(url, headers=headers, data=data)
Accessing Machines:
NOTE: Pending work will enable anyone connected to the VPN to SSH into the machines with the right keys/access/role privileges.
From the AWS console, assume the `edx-veda` role.
By clicking on individual instances, you should be able to see more information about these instances, including external IP address and security groups.

For example, this instance's security group is 'pipeline_secure'.
Click through to the security group tab. On the dialogue below, click the "Inbound" tab, click edit, and add your local public IP for port 22.
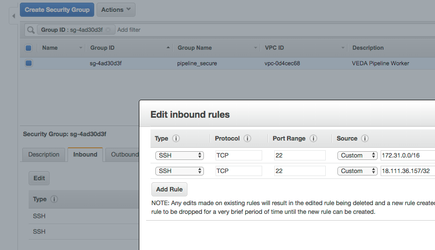
IMPORTANT NOTE:
Do NOT delete inbound rules. These are important for the cluster to communicate and function.
Now, ssh into the instance via the key that was added to the instance on startup. (Don't have an ssh key associated with the instance? You'll need to contact veda-ops)
ssh -i {pathtoyourkey} ec2-user@{ec2_instance_ip}
The ssh user is always ec2-user (unless it's an ubuntu machine, in which case it's ubuntu)
Restarting Processes
Encode:
Verify that no processes are running with:
ps ax | grep worker
Run the following command
NEW_RELIC_CONFIG_FILE=/home/ec2-user/edx-video-worker/veda_newrelic.ini newrelic-admin run-program nohup /home/ec2-user/edx-video-worker/worker.sh &> /home/ec2-user/logs/worker.out &
Deliver:
- Verify that the deliver process is not running (it's a celery queue) via flower:

ssh into the deliver machine and run the following commands
export PYTHONPATH='/home/ec2-user/edx-video-pipeline' NEW_RELIC_CONFIG_FILE=/home/ec2-user/edx-video-pipeline/veda_newrelic.ini DJANGO_SETTINGS_MODULE='VEDA.settings.production' nohup newrelic-admin run-program /home/ec2-user/edx-video-pipeline/bin/deliver &>/home/ec2-user/logs/deliver.out &
Ingest:
- SSH into the pipeline_worker machine
Verify that the ingest process is not running via ps ax:
ps ax | grep ingest
Run the following commands
export PYTHONPATH='/home/ec2-user/edx-video-pipeline' NEW_RELIC_CONFIG_FILE=/home/ec2-user/edx-video-pipeline/veda_newrelic.ini DJANGO_SETTINGS_MODULE='VEDA.settings.production' nohup newrelic-admin run-program /home/ec2-user/edx-video-pipeline/bin/ingest &>/home/ec2-user/logs/ingest.out &
Youtube API Callback:
- SSH into the pipeline_worker machine
Verify that the ingest process is not running via ps ax:
ps ax | grep youtube
Run the following commands
export PYTHONPATH='/home/ec2-user/edx-video-pipeline' NEW_RELIC_CONFIG_FILE=/home/ec2-user/edx-video-pipeline/veda_newrelic.ini DJANGO_SETTINGS_MODULE='VEDA.settings.production' nohup newrelic-admin run-program /home/ec2-user/edx-video-pipeline/bin/youtubecallback &> /home/ec2-user/logs/youtube.out &
Viewing Logs (Temporary until Splunk is operational):
HTTP logs:
Veda - HTTP One & Two (separate machines) :
- ~/logs/uwsgi.out
- ~/logs/nginx.out
- ~/logs/error.out
Ingest logs:
Veda - Ingest Worker : ~/logs/ingest.out
Youtube Callback:
Veda - Ingest Worker : ~/logs/youtube.out
Deliver:
Veda - Deliver Worker : ~/logs/deliver.out
Encoding:
Encode worker (various) : ~/worker.out
Release Process
edx-video-pipeline and edx-video-worker are both released using simple terraform commands. The terraform plans are all contained within the edx/terraform repository, and only a basic understanding of terraform is necessary to do a release.
Generally, the only commands you'll need are terraform plan
terraform destroyterraform apply
Before Releasing:
You'll need a few things to destroy and rebuild EC2 instances. DevOps has some fine documentation on the process for getting this set up.
- An AWS Hub account with sufficient privileges to switch to the edx-veda IAM role.
- An SSH public/private key combo associated with your edx-veda IAM role account.
- Access to the veda-secure repo (via DevOps)
- Terraform installed.
Release:
edx-video-pipeline is the central HTTP, Ingest, and Deliverable nodes for VEDA. Effectively, it's the interface and routing logic behind video processing.
- Create release branch from master in the edx-video-pipeline repository
- Create a release branch, name it 'release_{ISODATE}' (e.g. release_010118)
- Push the branch to remote repository
- Create the release tag on master branch with the same name above
- Clone edx/terraform repository
- Navigate to the terraform/plans/veda directory. Here you should see several directories related to the various machines that VEDA needs to run.
- pipeline_worker (this is the worker that runs ingest and the youtube API callback)
- deliver (Delivery Node,
- This will be collapsed into the pipeline_worker once https://github.com/edx/edx-video-pipeline/pull/68 lands
- encode_workers (this redeploys edx-video-worker)
- http_one & http_two (this is the HTTP endpoint, behind a static ELB, allowing for a cheap version of blue-green deployment)
- rabbit (the rabbitMQ worker)
- sandbox (the terraform plan for building VEDA sandboxes)
- shared (this will be where we add files from the veda-secure repo)
- This will be altered by the Ansible work currently underway by the Mallow team, but is a manual process for now.
- Navigate to the terraform/plans/veda directory. Here you should see several directories related to the various machines that VEDA needs to run.
- Clone veda-secure repo in same root as the terraform repo (next to the terraform repo).
- REMEMBER TO GIT PULL
- Create a new terraform branch
- Assume edx-veda IAM role in terminal.
- Fill out the variables in the terraform.tfvars file.
- "pipeline_release" should have the value of your branch name created on step 1
- "veda_secure_directory" is the path to the directory that has the files checked out from https://github.com/edx-ops/veda-secure
- Make sure the path is specified to the top folder of the secure folder, and do have leave the trailing "/". For example: "~/work/veda-secure"
- For HTTP server types, the "rabbit_username" and "rabbit_password" comes from veda-secure repo. You can copy and past the values from there.
- Destroy Pipeline worker.
cd /terraform/plans/veda/pipeline_workerterraform destroy
- IF RELEASING WORKERS:
- Wait for celery queue to drain (Monitor via Flower)
- Destroy Deliver worker.
cd /terraform/plans/veda/deliverterraform destroy
- Destroy/Rebuild HTTP1.
cd /terraform/plans/veda/http_oneterraform plan- If this fails, there is a problem with the terraform plan. If you aren't facile with terraform, you should ask someone who is able to help you.
terraform apply- You will be prompted for a few variables:
local_ip(Your local machine's broadcast public IP, needed for running provisioning commands)pipeline_release(The new edx-video-pipeline release number)private_key_name(this is the name/filename of the ssh key you put in the AWS IAM console associated with your account in the edx-veda IAM role. It should end with a 'pem' suffix)- rabbit_user (this is available in the instance_config file in the /veda/shared folder)
- rabbit_pass (see above)
- The plan will run, rebuilding the HTTP worker with the new release.
- You will be prompted for a few variables:
- Destroy/Rebuild HTTP2.
cd /terraform/plans/veda/http_two- Repeat steps 10b - 10c
- Rebuild Deliver Worker.
cd /terraform/plans/veda/deliver- Repeat steps 9b-9c (will not need rabbit pass information)
- Rebuild pipeline worker.
cd /terraform/plans/veda/pipeline_worker- Repeat step 9b (will not need rabbit pass information)
- Note the release and any notes below
- Make a PR against the terraform repo, making sure to note that DevOps SHOULD NOT run the plans (as you have already done so)
- Make a PR against edx-video-pipeline with any debug changes in the release branch.
Releases (add newer to top):
| Date/Time | Deployed | Terraform PR/Debug PR | Notes |
|---|---|---|---|
| 06.12.2017T07:30+0500 | https://github.com/edx/edx-video-pipeline/releases/tag/1.2.1 https://github.com/edx/edx-video-pipeline/releases/tag/1.2.1b | A secondary bugfix was pushed for this release (1.2.1b) on the same branch. Release branch is being merged back into | |
| 17.11.2017T16:00+0500 | https://github.com/edx/edx-video-pipeline/releases/tag/1.2.0 | ||
| 06.11.2017T13:00+0500 | https://github.com/edx/edx-video-pipeline/releases/tag/1.1.1 | ||
| 16.10.2017T16:00+0400 | https://github.com/edx/edx-video-pipeline/pull/22 | https://github.com/edx/terraform/pull/678 |