BlobStore API (and AssetMgr) Details
- Julia Eskew (Deactivated)
- Ty Hob
Objective
Document a detailed final design for storing and retrieving course assets. The final design will help inform the phased-in steps along the way - so it's important that we're in agreement on it. The initial design is located here: GridFS Replacement
Asset Write (App Upload) Flow
Diagram
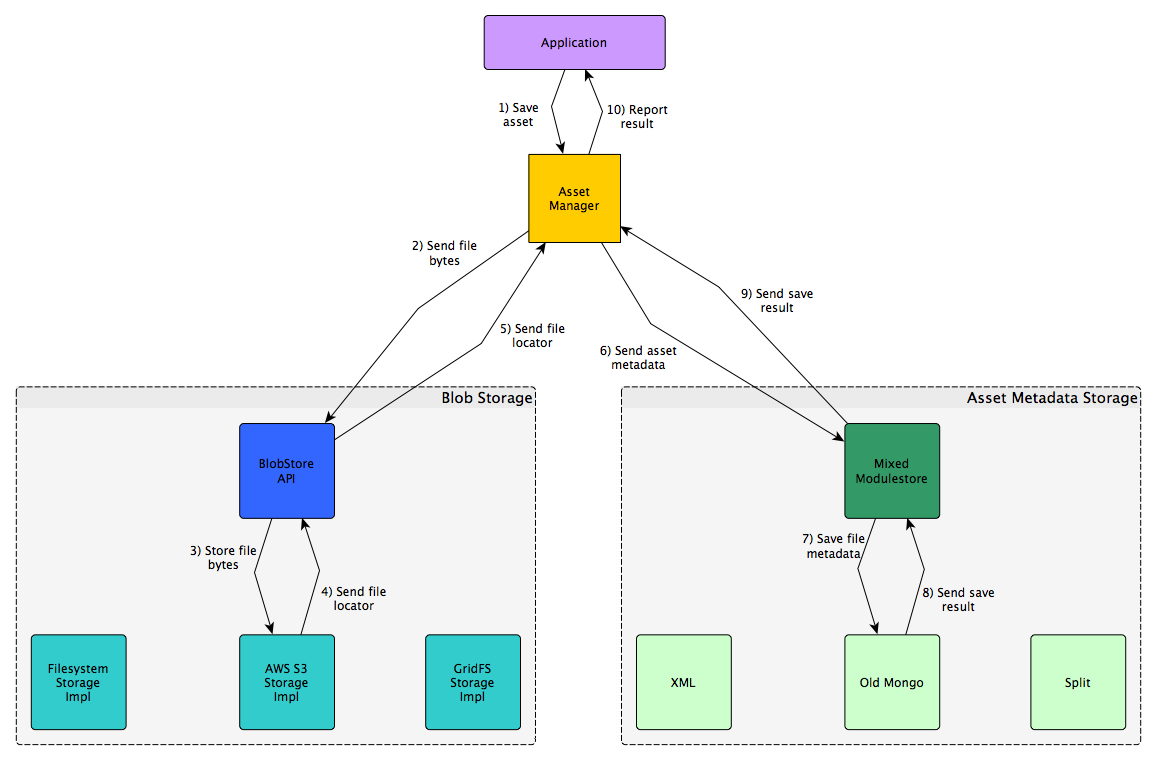
Description
- Course author uploads a course asset via Studio. The application code calls the "Asset Manager" (AssetMgr) - this is a replacement name for the Contentstore Re-direct (CSR) name we've been using until now.
- Params:
- CourseKey
- actual asset bytes
- uploaded filepath (filename + path to file)
- locked/unlocked attribute
- possibly other attributes
- Params:
- The AssetMgr looks up the StorageID used for the course in the modulestore.
- The CourseKey is used to look up the StorageID.
- It's stored with all the assets in the relevant modulestore.
- The AssetMgr calls the BlobStore API call to store an asset.
- store_blob - API method that can be used platform-wide to store blobs
- Params:
- StorageID used for course
- actual blob bytes
- file pathname
- additional blob attributes
- Using the StorageID, the proper storage impl's
store_blob()is called.- At this point, the particular storage impl takes over.
- It must:
- Save the file bytes or identify an existing copy of the file.
- Send back a BlobLocator that can be used to find that file in the relevant storage.
- The StorageID should be introspectable from the BlobLocator.
- It can (optionally):
- Send back a version number for the saved file.
- Save introspection data of some sort along with the file (if the storage supports it).
- Send back whatever fields are needed/desired to be saved along with the asset metadata.
- The asset file locator (BlobLocator) is sent back to the AssetStore API.
- BlobLocators will provide common properties:
- storage: StorageID
- version: string which can be something relevant or None or empty
- filepath: string identifying path to file, including filename
- (maybe) hash: string representing file hash
- (maybe) hash_type: string representing hash algorithm used to generate hash
- other_props: dict of properties to save with metadata and send back whenever accessing asset
- BlobLocators will provide common properties:
- The BlobLocator is returned from the BlobStore API back to the AssetMgr.
- If the file save was unsuccessful, end here and return error result to application.
- NOTE: The BlobLocator can be used to retrieve the asset at this point.
- The BlobStore API works independently of the rest of this flow.
- This point is important! It'll enable other parts of the application to store course things, like ORA data and such.
- The AssetMetadata is sent to the Mixed Modulestore.
- An AssetMetadata object contains an BlobLocator - the one sent back from the BlobStore API.
- But it also contains the CourseKey and other attributes sent from the application.
- The Mixed Modulestore knows which modulestore is used for the course.
- It forwards the AssetMetadata on to the appropriate modulestore.
- The modulestore saves the asset metadata in the appropriate location.
- This is the subject of my pending PR: https://github.com/edx/edx-platform/pull/4854
- If asset metadata is already stored for the particular asset, it's updated appropriately.
- The result of saving the asset metadata is returned to the Mixed Modulestore.
- It's possible that XML-backed courses will always return error here?
- Mixed modulestore returns the result back to the AssetMgr.
- If the asset was stored successfully but the metadata save failed, perhaps delete the stored asset.
- The total asset storage result is sent back to the calling application.
Asset Read Flow
Diagram

Description
- Student requests a course asset. Application calls the AssetMgr with an AssetKey.
- AssetKey is sent to the Mixed Modulestore.
- It knows the modulestore that's used for the asset's course.
- Search for the AssetMetadata in the appropriate modulestore.
- Also the subject (for old Mongo) of my pending PR: https://github.com/edx/edx-platform/pull/4854
- Return the AssetMetadata to the Mixed Modulestore.
- Return the AssetMetadata to the AssetMgr.
- Check the asset's attributes in the metadata.
- If an asset is locked, the AssetMgr checks the user access permissions to see if access is allowed.
- If access is not allowed, return a 404.
- Extract the blob_key (BlobLocator) from the asset metadata.
- If no asset metadata was found for the requested asset:
- Form a BlobLocator containing a SON object pointing to the GridFS-stored asset.
- This step yields backwards-compatibility with the contentstore-stored assets.
- Form a BlobLocator containing a SON object pointing to the GridFS-stored asset.
- AssetMgr calls the BlobStore API
get_asset(blob_key, ttl_seconds)call.- The blob_key allows introspection of the relevant storage impl.
- The ttl_seconds param is relevant when the asset is locked.
- That's how the locked attribute is communicated forward.
- BlobStore API calls the relevant storage impl.
- It knows which storage impl should have the asset via the StorageID in the BlobLocator.
- The storage impl does one of two things. Either a) or b):
- generates a URL which can be used to access the course asset.
- This can be an internal c4x URL or an external AWS URL ( or a shortened "pretty" URL).
- Blobs stored externally (like S3) or accessible via the webserver (like filesystem) have URLs returned - not the actual blobs.
- returns the actual blob bytes
- Blobs stored internally with no external access allowed have bytes returned - like GridFS.
- generates a URL which can be used to access the course asset.
- BlobStore API returns URL or bytes to the AssetMgr.
- AssetMgr returns result to application.
- If URL, AssetMgr redirects the student to the returned URL.
- If bytes, then done.
Other Course Asset Metadata Storage
The modulestore API used to store course asset metadata has been written to allow other systems to store asset metadata of other types, such as video. Those systems would not use the AssetMgr but would instead access the modulestore directly via the Mixed Modulestore, as shown below. However, the systems which store asset metadata in the system are responsible for their own storage & tracking and for handling access authentication if locked assets are desired.

BlobStore API
store_blob
Method which stores the bytes of a blob and returns a BlobLocator that allows the blob to be retrieved later.
Parameters:
- file pathname
- File path and basename (e.g. "textbook/chapter1/section1.pdf")
- Or a simple blobname.
- blob bytes
- All the bytes of the blob.
- StorageID
- ID of the storage impl in which to store the blob
- additional_attrs
- Dict of additional information about the asset
- For example, course ID.
- Storage impl might/might not use this information.
- Dict of additional information about the asset
Returns:
- BlobLocator
- Contains:
- Storage implementation used (S3, GridFS, filesystem, etc.)
- Size
- All information needed to retrieve this exact asset from this storage impl
- Contains:
append_to_blob
Method which appends more bytes to an already-existing blob.
Parameters:
- BlobLocator
- Only already-stored blobs would have a BlobLocator.
- blob bytes
- Bytes to append to the blob.
Returns:
- BlobLocator
- Updated BlobLocator.
get_blob
Method which retrieves a blob's bytes.
Parameters:
- BlobLocator
- Byte range of the blob (optional)
Returns:
- Bytes of the blob (all bytes or partial bytes if byte range specified)
get_blob_url
Method which retrieves a blob's URL which can be used to directly retrieve the blob.
Parameters:
- BlobLocator
- Byte range of the blob (optional)
Returns:
- URL for download of externally-stored blob
Questions To Resolve:
- Upon asset read, will the AssetMgr always return an asset URL to the application, no matter which AssetStore storage backend is used?
- With S3, it must send back a URL - those assets are stored externally.
- But for GridFS, it currently sends back the bytes themselves.
- Maybe send back the actual bytes when using GridFS/Filesystem but re-direct to external URL with S3?
- CURRENT THINKING:
- Return the blob when possible - when the blob is stored internally to the application, like in GridFS.
- Return an external URL for the blob when the blob is stored externally, like in S3.
- When the blob is accessible via the webserver outside the application, return a URL to the blob, like in filesystem storage.
- The webserver will serve up the blob outside of the application - the app will only provide the URL.
- Does it make sense to change AssetStore to BlobStore?
- BlobStore would be a general-purpose API for storing/retrieving binary assets for the whole edX platform.
- The current design calls for a per-course configuration of where assets are stored.
- Using the BlobStore platform-wide would mean storing non-course-specific assets as well.
- What logic would decide which storage backend to use for each stored blob?
- Would the API accept a passed-in storage preference?
- There's currently several ad-hoc implementations of S3 storage using boto throughout the platform code.
- A BlobStore could be used by all that code, plus any future code that needed to store binary assets.
- CURRENT THINKING:
- A BlobStore with a clear, separated API makes sense.
- Blobs would be stored unassociated with courses.
- A BlobLocator would be returned for each stored asset.
- It's the key that returns the stored blob.
- Where does the storage location of an asset get stored?
- We've decided on a transition model that would allow for an asset to be in either the new AssetStore storage or in the Contentstore.
- Suppose an asset's metadata is present in the course's modulestore.
- Then in which storage backend will the asset be located?
- It seems like the storage backend needs to be stored in the asset metadata itself.
- Suppose an asset's metadata is present in the course's modulestore.
- Consider the following use case:
- DevOps detects a problem with a particular course asset's downloads.
- The course currently has all its assets stored in GridFS.
- DevOps switches the course's asset storage impl from GridFS to S3.
- One of the following is performed:
- Upload as new asset
- DevOps uploads the relevant asset under a new name, which is stored in S3.
- The course is updated to point to the new asset.
- The old GridFS-stored asset is deleted (optionally).
- Delete/Upload
- DevOps deletes the relevant asset.
- The asset is uploaded with the same name to S3.
- Upload as new asset
- At this point, a single course asset is stored in one storage implementation (S3) and the rest are in another (GridFS).
- The top-level storage implementation for the course should indicate where any new assets are stored.
- But each asset's metadata should indicate in which storage implementation the asset is currently stored.
- This sounds resolved now!....
- RESOLUTION: Each asset's metadata (specifically, the BlobLocator inside the AssetStoreLocator, as above) identifies the storage impl used for the asset.
- We've decided on a transition model that would allow for an asset to be in either the new AssetStore storage or in the Contentstore.
- How should the BlobStore API be secured via authentication?
- Ideally, only internal edX platform code should be able to call the BlobStore API (for now).
- How should that be enforced?
- IP address checks? Secret key?
- Handing back a temporary URL from S3 will be problematic in regards to browser caching.
- The URL will likely be different on every access of a course asset.
- A different URL to the same asset will cause a re-download of a cached asset.
- RESOLUTION: Consider this issue and attempt to enable browser caching when implementing the S3 storage impl.
- Perhaps do a timed reset of URLs handed out for assets, to extend their time in the browser cache.
Work Progression
- Saving of asset metadata in all relevant modulestores.
- Per-asset and coursewide
- Reading of asset metadata from all relevant modulestores.
- Per-asset and coursewide
- Read wrapper serving all asset requests.
- Serves all assets from the contentstore (GridFS) as per usual.
- Write wrapper around all asset saves/updates.
- Write all assets to the contentstore (GridFS) as per usual.
- Implement cross-asset-storage functions.
- For eventual situation when course assets are stored in both the contentstore and the modulestore.
- Implement course asset listing in Studio when assets in both places.
- Implement course export when assets in both places.
- Write tests.
- Create BlobStore GitHub project.
- Implement BlobStore Python API.
- Public-facing API that:
- Introspects a passed-in blob_key.
- Routes the request to the appropriate storage implementation.
- Flexible enough to return URL to download blob or actual blob bytes.
- Pluggable storage implementation architecture.
- Properly configured storage implementations become available at runtime.
- Implement get_storages().
- Implement a "blackhole" storage impl first.
- Doesn't actually save anything, but is pluggable and returns sane values.
- Implement save_blob()/append_to_blob()/get_blob().
- Public-facing API that:
- Implement GridFS storage impl.
- Uses blob_key to find existing GridFS-stored content in fs.files/fs.chunks.
- get_blob() uses SON object in BlobLocator and returns blob bytes.
- A lot of the implementation will be directly lifted from MongoContentStore().
- Implement S3 storage impl.
- Generate hash for asset bytes.
- Upload asset bytes to S3, named appropriately.
- Uses blob_key to generate URL to S3-stored asset.
- URL can be permanent or temporary (time-based).
- Possible: De-duplicate the assets using the hash value.
Transition Plan
Initially all assets are in GridFS - no asset metadata exists in the modulestore.
Phase One:
- Wrap all asset reads with AssetMgr.
- Checks for asset metadata in modulestore - but never finds it.
- Still reads assets from contentstore.
Phase Two:
- Wrap all asset reads & writes with AssetMgr.
- As above for reads.
- Writes perform a simple pass-through to the contentstore.
Phase Three:
The largest leap. BlobStore API is complete and GridFS storage implementation is functional. Asset reads/writes work as follows:
Asset Reads
Assets reads will read the assets from GridFS exactly as they are stored today. No conversion (active or lazy) or import/export needs to take place.
- AssetMgr attempts to find the asset in the asset metadata.
- When not found, the AssetMgr forms a BlobLocator itself.
- Has a StorageID of "gridfs"
- Storage-impl-only details have a SON object (or the info needed to construct a SON object).
- Constructed BlobLocator is sent over to BlobStore API in get_blob().
- BlobStore API routes the BlobLocator and get_blob() call to the GridFS pluggable impl.
- The GridFS impl uses the SON object to access the blob bytes.
- Returns the bytes.
Asset Writes
Asset writes will function just as they eventually will (see diagram above). However, new assets stored in GridFS will pass back a BlobLocator with a MongoDB document ObjectId instead of a SON object. The GridFS storage impl needs to be able to query blobs using both.
Studio Asset List
Asset metadata will now be stored in two different locations - contentstore and modulestore. When a list of all course assets is needed, as in the Files & Uploads view in Studio, asset metadata will need to be pulled from both places, combined, sorted, and paged through.
Course Import/Export
Course import will cause all asset metadata to be stored in the modulestore only, with the actual bytes stored in the BlobStore (GridFS storage impl) - no assets will remain in the contentstore after import.
Course export will need to pull assets from both the modulestore/BlobStore and the contentstore for storage in the course tarball.
Course Reruns
As in course imports, course reruns will cause all asset metadata to be stored in the modulestore only, with the actual bytes stored in the BlobStore (GridFS storage impl) - no asset will remain in the contentstore after a rerun.
Phase Four:
S3 storage implementation is functional. Global and per-course storage impl preference is implemented.
Asset Reads
Asset reads function as above - but might also be stored in S3 now.
Asset Writes
Asset writes can be configured to go to S3 (per-course or globally).
Studio Asset Listing
The asset listing will function as in Phase 3 above - looking for assets in both the modulestore/BlobStore and the contentstore.
Course Import/Export
Course import will cause all asset metadata to be stored in the modulestore only, with the actual bytes in the BlobStore GridFS or S3 storage impls - whichever one is configured as the course's default storage impl. No assets will remain in the contentstore after import.
Course export will function as in Phase 3 - pulling from both the modulestore/BlobStore and the contentstore.
Course Reruns
As in course imports, course reruns will cause all asset metadata to be stored in the modulestore only, with the actual bytes in the BlobStore GridFS or S3 storage impls - whichever one is configured as the course's default storage impl. No assets will remain in the contentstore after import.
Asset Metadata in Course XML
One implication to the course asset metadata moving from the contentstore to the modulestore is that the format used to store the asset metadata in an exported course will change. Currently, all the asset metadata in the contentstore is exported to an assets.json file and stored in the top-level "policies" directory of an exported course. The modulestore-stored asset metadata will no longer export to that location. Instead, it'll be exported to XML directly. An exported course will potentially have asset metadata in both XML and in the assets.json file - course import will need to read from both locations. The assets themselves will remain in the top-level "static" directory of an exported course.
Asset XML Format
The XML format of the asset metadata will be formalized by an XML schema definition (XSD), which follows:
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="assets" type="assetListType" />
<xs:simpleType name="stringType">
<xs:restriction base="xs:string"/>
</xs:simpleType>
<xs:simpleType name="userIdType">
<xs:restriction base="xs:nonNegativeInteger"/>
</xs:simpleType>
<xs:simpleType name="datetimeType">
<xs:restriction base="xs:dateTime"/>
</xs:simpleType>
<xs:simpleType name="boolType">
<xs:restriction base="xs:boolean"/>
</xs:simpleType>
<xs:complexType name="assetListType">
<xs:sequence>
<xs:element name="asset" type="assetType" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="assetType">
<xs:all>
<xs:element name="asset_id" type="stringType"/>
<xs:element name="contenttype" type="stringType"/>
<xs:element name="basename" type="stringType"/>
<xs:element name="internal_name" type="stringType"/>
<xs:element name="locked" type="boolType"/>
<xs:element name="thumbnail" type="stringType" minOccurs="0"/>
<xs:element name="created_on" type="datetimeType" />
<xs:element name="created_by" type="userIdType" />
<xs:element name="created_by_email" type="stringType" minOccurs="0"/>
<xs:element name="edited_on" type="datetimeType" />
<xs:element name="edited_by" type="userIdType" />
<xs:element name="edited_by_email" type="stringType" minOccurs="0"/>
<xs:element name="prev_version" type="stringType"/>
<xs:element name="curr_version" type="stringType"/>
<xs:element name="fields" type="stringType" minOccurs="0"/>
</xs:all>
</xs:complexType>
</xs:schema>
The XSD above formalizes the XML structure shown below:
<assets>
<asset>
<asset_id>AssetKey("pic1.jpg")</asset_id>
<contenttype>None</contenttype>
<curr_version>14</curr_version>
<basename>pix/archive</basename>
<edited_on>2014-11-17T21:02:38</edited_on>
<created_on>2014-11-17T21:02:38</created_on>
<created_by>14</created_by>
<prev_version>13</prev_version>
<edited_by>14</edited_by>
<internal_name>EKMND332DDBK</internal_name>
<fields>{"size": 8686848, "copyrighted": 0}</fields>
<locked>false</locked>
<thumbnail>None</thumbnail>
</asset>
...
</assets>
Further Notes
- When course assets are served in the current platform, they go through the StaticContentServer() in
common/djangoapps/contentserver/middleware.py- This is Django middleware that:
- intercepts the "c4x/" links
- checks if the requestor is in the course
- enforces "locked" (if set)
- serves from memcache, if possible
- caches the asset, if possible
- serves a partial byte amount, if desired
- returns an HTTP response
- This is Django middleware that: