...
- The production process of getting files into S3 will be:
- A Tubular script is run on a cron via Jenkins
- The script gathers old retirements from LMS and creates a gzipped JSON archive file
- The archive file is uploaded to S3
- The archived retirements are permanently deleted from the LMS database
- For testing the Platform team can provide some properly formatted files
Configure Athena
- I used the AWS Console for this, though database creation can be handled by Terraform
- Make sure you are in the same region as the S3 bucket you created (check top right of the console). Encrypted buckets can only be queried in the same region.
- To create connect to a database data source you must go through the "create tableconnect data source" workflow by clicking on the "Create tableConnect Data Source" link and selecting "From S3 bucket- AWS Glue Data Catalog"
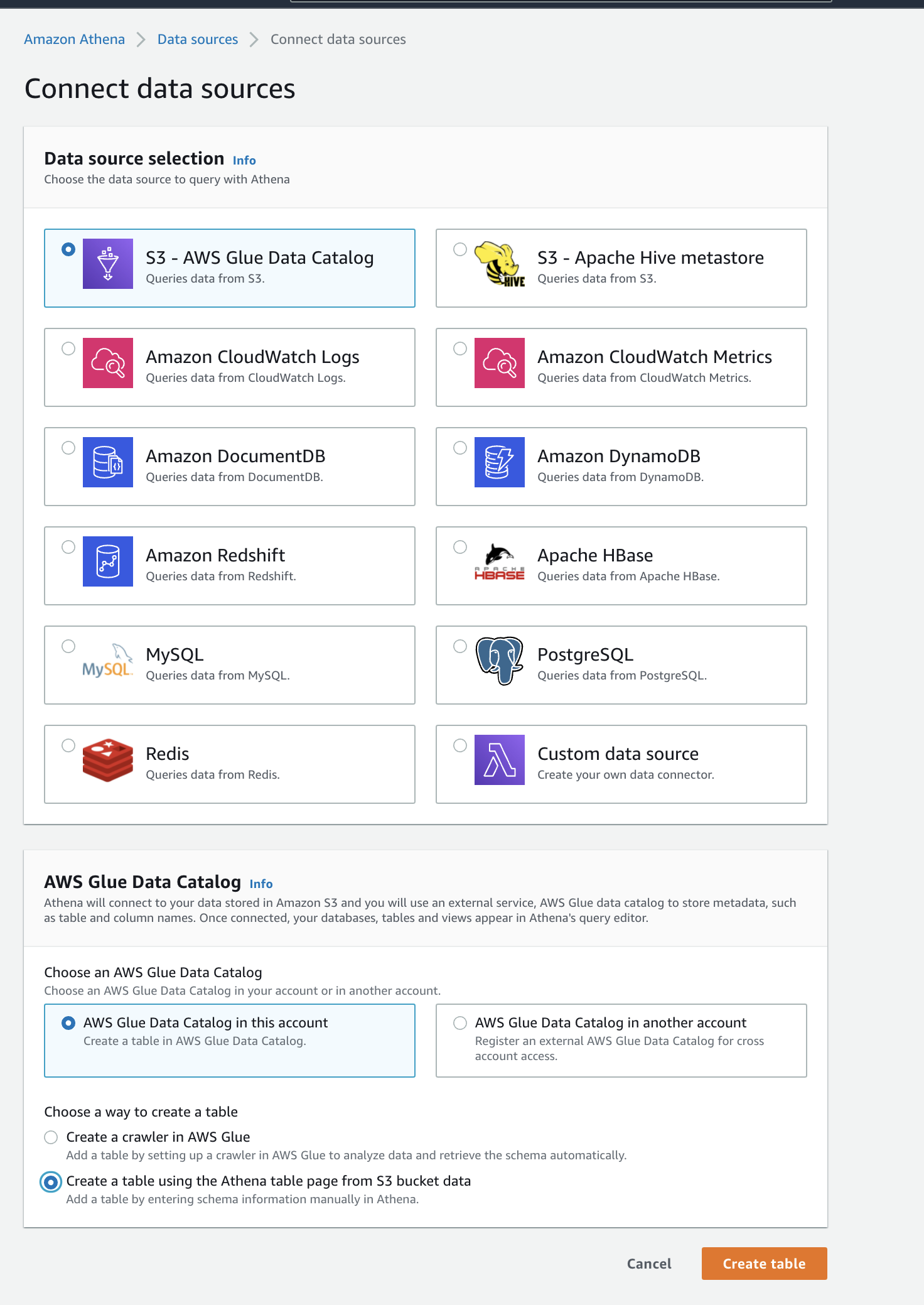
- Step 1: Name & Location
- Under database select "Create new database"
- Put in your database and table names and the S3 bucket in "Location of input data set" (ex: s3://athena-test-2018-10-23/)
- Check the "Encrypted data set" box!
- Leave the "External" box checked. You can't uncheck it anyway.
- Step 2: Data Format
- Select JSON
- Step 3: Columns
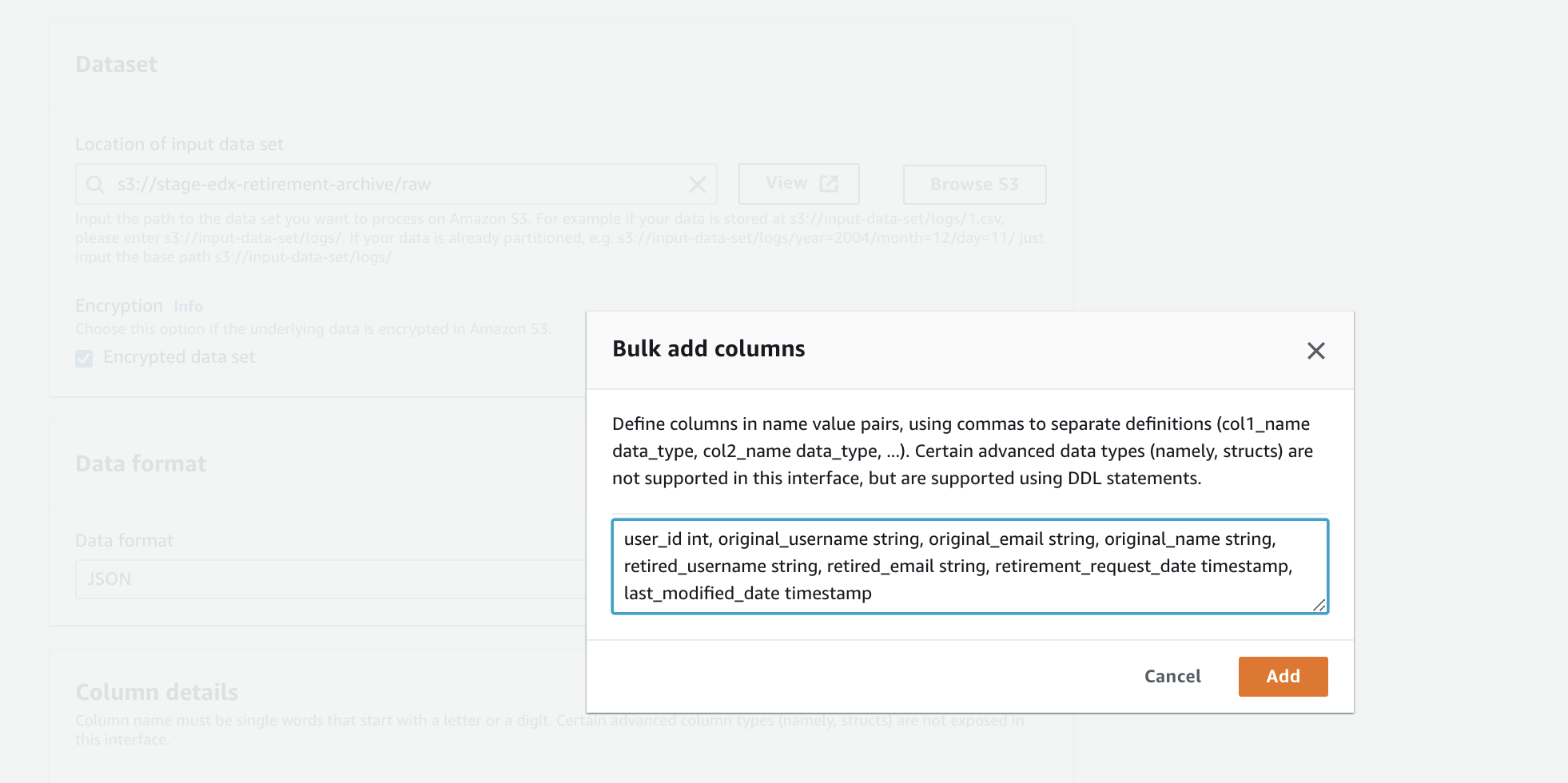
- Click "Bulk Add Columns"
- Paste this in:
user_id int, original_username string, original_email string, original_name string, retired_username string, retired_email string, retirement_request_date timestamp, last_modified_date timestamp
- Click "Add"
- Step 4: Partitions
- I did not add any
- Click "Create Table" and you're done.
...