Domain-Driven Design Book Club Notes
- Nimisha Asthagiri (Deactivated)
- Gabe Mulley (Deactivated)
- Robert Raposa
Preface
Quotes
"As the team gained new insight into the domain, the model deepened. The quality of communication improved not only among developers but also between developers and domain experts, and the design—far from imposing an ever-heavier maintenance burden—became easier to modify and extend."
"The Extreme Programming process assumes that you can improve a design by refactoring, and that you will do this often and rapidly."
Part 1
Quotes
"It is not just the knowledge in a domain expert’s head; it is a rigorously organized and selective abstraction of that knowledge."
Model Usage
- The model and the heart of the design shape each other.
- The model is the backbone of a language used by all team members.
- The model is distilled knowledge.
Developer motivation
- "Domain work is messy and demands a lot of complicated new knowledge that doesn’t seem to add to a computer scientist’s capabilities."
- "Instead, the technical talent goes to work on elaborate frameworks, trying to solve domain problems with technology. Learning about and modeling the domain is left to others. Complexity in the heart of software has to be tackled head-on."
- "There are systematic ways of thinking that developers can employ to search for insight and produce effective models. There are design techniques that can bring order to a sprawling software application. Cultivation of these skills makes a developer much more valuable, even in an initially unfamiliar domain."
Chapter 1 Crunching Knowledge and Chapter 2 Communication and the Use of Language
Quotes
"Design and Process are inextricable."
“The domain model will typically derive from the domain experts’ own jargon but will have been “cleaned up,” to have sharper, narrower definitions.”
“A document shouldn’t try to do what the code already does well. The code already supplies the detail. It is an exact specification of program behavior. Other documents need to illuminate meaning, to give insight into large-scale structures, and to focus attention on core elements. Documents can clarify design intent when the programming language does not support a straightforward implementation of a concept. Written documents should complement the code and the talking.”
“It takes fastidiousness to write code that doesn’t just do the right thing but also says the right thing.”
Discussion
Chapter 3 Binding Model and Implementation and Chapter 4 Isolating the Domain
Quotes
“Software development is all design. All teams have specialized roles for members, but over separation of responsibility for analysis, modeling, design, and programming interferes with MODEL-DRIVEN DESIGN.”
Example: “A user of Internet Explorer thinks of 'Favorites' as a list of names of Web sites that persist from session to session. But the implementation treats a Favorite as a file containing a URL, and whose filename is put in the Favorites list.”
“If the people who write the code do not feel responsible for the model, or don’t understand how to make the model work for an application, then the model has nothing to do with the software.”
“Every developer must be involved in some level of discussion about the model and have contact with domain experts.”
Discussion
Chapter 5 A Model Expressed in Software
Quotes
Intro
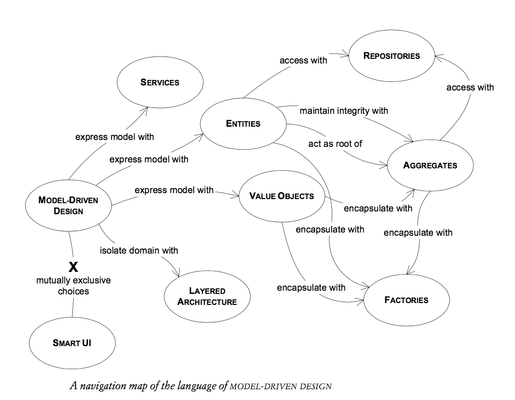
Does an object represent something with continuity and identity - something that is tracked through different states or even across different implementations? Or is it an attribute that describes the state of something else? This is the basic distinction between an ENTITY and a VALUE OBJECT. Defining objects that clearly follow one pattern or the other makes the objects less ambiguous and lays out the path toward specific choices for robust design.
Then there are those aspects of the domain that are more clearly expressed as actions or operations, rather than as objects. Although it is a slight departure from object-oriented modeling tradition, it is often best to express these as SERVICES, rather than forcing responsibility for an operation onto some ENTITY or VALUE OBJECT. A SERVICE is something that is done for a client on request. They emerge .. when some activity is modeled that corresponds to something the software must do, but does not correspond with state.
Associations
There are at least three ways of making associations more tractable:
- Imposing a traversal direction
- Adding a qualifier, effectively reducing multiplicity
- Eliminating nonessential associations
It is important to constrain relationships as much as possible. A bidirectional association means that both objects can be understood only together. When application requirements do not call for traversal in both directions, adding a traversal direction reduces interdependence and simplifies the design. Understanding the domain may reveal a natural directional bias.
Constraining the traversal direction of a many-to-many association effectively reduces its implementation to one-to-many - a much easier design.
Entity
An object defined primarily by its identity is called an ENTITY. ENTITIES have special modeling and design considerations. They have life cycles that can radically change their form and content, but a thread of continuity must be maintained. Their identities must be defined so that they can be effectively tracked. Their class definitions, responsibilities, attributes, and associations should revolve around who they are, rather than the particular attributes they carry. Even for ENTITIES that don't transform so radically or have such complicated life cycles, placing them in the semantic category leads to more lucid models and more robust implementations.
When an object is distinguished by its identity, rather than its attributes, make this primary to its definition in the model. Keep the class definition simple and focused on life cycle continuity and identity.
Value Objects
Software design is a constant battle with complexity. We must make distinctions so that special handling is applied only where necessary. VALUE OBJECTS are instantiated to represent elements of the design that we care about only for what they are, not who or which they are.
When you care only about the attributes of an element of the model, classify it as a VALUE OBJECT. Make it express the meaning of the attributes it conveys and give it related functionality. Treat the VALUE OBJECT as immutable. Don't give it any identity and avoid the design complexities necessary to maintain ENTITIES.
As long as a VALUE OBJECT is immutable, change management is simple - there isn't any change except full replacement. Immutable objects can be freely shared, as in the electrical outlet example. If garbage collection is reliable, deletion is just a matter of dropping all references.
Try to completely eliminate bidirectional associations between VALUE OBJECTS.
Services
A SERVICE is an operation offered as an interface that stands alone in the model, without encapsulating state, as ENTITIES and VALUE OBJECTS do. SERVICES are a common pattern in technical frameworks, but they can also apply in the domain layer. They are intrinsically activities or actions, not things.
A good SERVICE has three characteristics.
- The operation relates to a domain concept that is not a natural part of an ENTITY or VALUE OBJECT.
- The interface is defined in terms of other elements of the domain model.
- The operation is stateless.
It takes care to distinguish SERVICES that belong to the domain layer from those of other layers, and to factor responsibilities to keep that distinction sharp. Layers:
- Application service
- Domain service
- Infrastructure service
Granularity
Medium-grained, stateless SERVICES can be easier to reuse in large systems because they encapsulate significant functionality behind a simple interface. Also, fine-grained objects can lead to inefficient messaging in a distributed system.
As previously discussed, fine-grained domain objects can contribute to knowledge leaks from the domain into the application layer, where the domain object's behavior is coordinated. The complexity of a highly detailed interaction ends up being handled in the application layer, allowing domain knowledge to creep into the application or user interface code, where it is lost from the domain layer
Modules (Packages)
It is a truism that there should be low coupling between MODULES and high cohesion within them. Explanations of coupling and cohesion tend to make them sound like technical metrics, to be judged mechanically based on the distributions of associations and interactions. Yet it isn't just code being divided into MODULES, but concepts. There is a limit to how many things a person can think about at once (hence low coupling). Incoherent fragments of ideas are as hard to understand as an undifferentiated soup of ideas (hence high cohesion).
..tiered architectures can fragment the implementation of the model objects. Some frameworks create tiers by spreading the responsibilities of a single domain object across multiple objects and then placing those objects in separate packages. At that point, viewing the various objects and mentally fitting them back together as a single conceptual ENTITY is just too much effort.
Unless there is a real intention to distribute code on different servers, keep all the code that implements a single conceptual object in the same MODULE, if not the same object.
Discussion
Chapter 6 Life Cycle of a Domain Object
Quotes
Aggregates, Factories, Repositories
- AGGREGATES tighten up the model itself by defining clear ownership and boundaries, avoiding a chaotic, tangled web of objects. This pattern is crucial to maintaining integrity in all phases of the life cycle.
- using FACTORIES to create and reconstitute
- REPOSITORIES address the middle and end of the life cycle, providing the means of finding and retrieving persistent objects while encapsulating the immense infrastructure involved.
Aggregates
Cluster the ENTITIES and VALUE OBJECTS into AGGREGATES and define boundaries around each. Choose one ENTITY to be the root of each AGGREGATE, and control all access to the objects inside the boundary through the root. Allow external objects to hold references to the root only. Transient references to internal members can be passed out for use within a single operation only. Because the root controls access, it cannot be blindsided by changes to the internals.
Example: denormalize price to satisfy Purchase Order Aggregate invariant.
Now, to translate that conceptual AGGREGATE into the implementation, we need a set of rules to apply to all transactions.
The root ENTITY has global identity and is ultimately responsible for checking invariants.
Root ENTITIES have global identity. ENTITIES inside the boundary have local identity, unique only within the AGGREGATE.
Nothing outside the AGGREGATE boundary can hold a reference to anything inside, except to the root ENTITY. The root ENTITY can hand references to the internal ENTITIES to other objects, but those objects can use them only transiently, and they may not hold on to the reference. The root may hand a copy of a VALUE OBJECT to another object, and it doesn't matter what happens to it, because it's just a VALUE and no longer will have any association with the AGGREGATE.
As a corollary to the previous rule, only AGGREGATE roots can be obtained directly with database queries. All other objects must be found by traversal of associations.
Objects within the AGGREGATE can hold references to other AGGREGATE roots.
A delete operation must remove everything within the AGGREGATE boundary at once. (With garbage collection, this is easy. Because there are no outside references to anything but the root, delete the root and everything else will be collected.)
When a change to any object within the AGGREGATE boundary is committed, all invariants of the whole AGGREGATE must be satisfied.
Factories
Creation of an object can be a major operation in itself, but complex assembly operations do not fit the responsibility of the created objects. Combining such responsibilities can produce ungainly designs that are hard to understand. Making the client direct construction muddies the design of the client, breaches encapsulation of the assembled object or AGGREGATE, and overly couples the client to the implementation of the created object.
The two basic requirements for any good FACTORY are:
- Each creation method is atomic and enforces all invariants of the created object or AGGREGATE. A FACTORY should only be able to produce an object in a consistent state.
- The FACTORY should be abstracted to the type desired, rather than the concrete class(es) created.
I refer to the creation of an instance from stored data as reconstitution. A FACTORY used for reconstitution is very similar to one used for creation, with two major differences:
- An ENTITY FACTORY used for reconstitution does not assign a new tracking ID. To do so would lose the continuity with the object's previous incarnation.
- A FACTORY reconstituting an object will handle violation of an invariant differently.
Repositories
- Abstract the type of the object returned
- Take advantage of the decoupling from the client.
- Leave transaction control to the client.
The FACTORY makes new objects; the REPOSITORY finds old objects.
These two views can be reconciled by making the REPOSITORY delegate object creation to a FACTORY, which (in theory, though seldom in practice) could also be used to create objects from scratch.
One other case that drives people to combine FACTORY and REPOSITORY is the desire for find or create functionality, in which a client can describe an object it wants and, if no such object is found, will be given a newly created one. This function should be avoided.
A table row should contain an object, perhaps along with subsidiaries in an AGGREGATE. A foreign key in the table should translate to a reference to another ENTITY object. The necessity of sometimes deviating from this simple directness should not lead to total abandonment of the principle of simple mappings.
Questions
- I wonder why he recommends that the Repository be the primary interface for reconstituting objects - rather than letting the Factory be the primary.
Discussion
Chapter 7 Example of Using the Language & 8 Breakthrough
Discussion
Chapter 9 Making Implicit Concepts Explicit
Quotes
- Experimentation is the way to learn what works and doesn't. Trying to avoid missteps in design will result in a lower quality result because it will be based on less experience. And it can easily take longer than a series of quick experiments.
- The key to distinguishing a process that ought to be made explicit from one that should be hidden is simple: Is this something the domain experts talk about, or is it just part of the mechanism of the computer program?
- Constraints and processes are two broad categories of model concepts that don't come leaping to mind when programming in an object-oriented language, yet they can really sharpen up a design once we start thinking about them as model elements.
- Create explicit predicate-like VALUE OBJECTS for specialized purposes. A SPECIFICATION is a predicate that determines if an object does or does not satisfy some criteria.
- The SPECIFICATION keeps the rule in the domain layer. Because the rule is a full-fledged object, the design can be a more explicit reflection of the model.
Discussion
Chapter 10 Supple Design
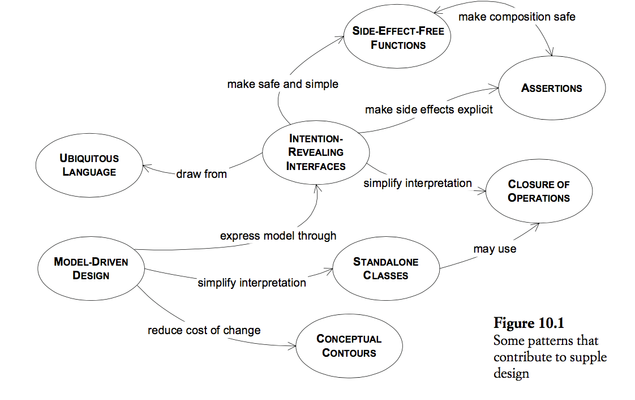
Quotes
- Intention-revealing interfaces allow clients to present objects as units of meaning rather than just mechanisms.
- Side-effect-free functions and Assertions make it safe to use those units and make complex combinations.
- The emergence of Conceptual Contours stabilizes parts of the model and also makes the units more intuitive to use and combine.
Intention-revealing interfaces
If a developer must consider the implementation of a component in order to use it, the value of encapsulation is lost.
Name classes and operations to describe their effect and purpose, without reference to the means by which they do what they promise.
Side-effect-free functions
Most operations call on other operations, and those called invoke still other operations. As soon as this arbitrarily deep nesting is involved, it becomes very hard to anticipate all the consequences of invoking an operation.
Functions are much easier to test than operations that have side effects. For these reasons, functions lower risk.
Strictly segregate commands (methods that result in modifications to observable state) into very simple operations that do not return domain information. Further control side effects by moving complex logic into VALUE OBJECTS when a concept fitting the responsibility presents itself.
Assertions
ASSERTIONS make side effects explicit and easier to deal with.
All these assertions describe state, not procedures, so they are easier to analyze.
State post-conditions of operations and invariants of classes and AGGREGATES. If ASSERTIONS cannot be coded directly in your programming language, write automated unit tests for them. Write them into documentation or diagrams where it fits the style of the project’s development process.
Conceptual Contours
One reason why repeated refactoring eventually leads to suppleness: the CONCEPTUAL CONTOURS emerge as the code is adapted to newly understood concepts or requirements.
Decompose design elements (operations, interfaces, classes, and AGGREGATES) into cohesive units, taking into consideration your intuition of the important divisions in the domain.
The goal is a simple set of interfaces that combine logically to make sensible statements in the UBIQUITOUS LANGUAGE, and without the distraction and maintenance burden of irrelevant options. This is typically an outcome of refactoring: it’s hard to produce up front. But it may never emerge from technically oriented refactoring; it emerges from refactoring toward deeper insight.
Standalone Classes
Low coupling is fundamental to object design. When you can, go all the way. Eliminate all other concepts from the picture. Then the class will be completely self-contained and can be studied and understood alone. Every such self-contained class significantly eases the burden of understanding a MODULE.
The goal is not to eliminate all dependencies, but to eliminate all nonessential ones. If every dependency can’t be eliminated, each one that is removed frees the developer to concentrate on the remaining conceptual dependencies.
Low coupling is a basic way to reduce conceptual overload. A STANDALONE CLASS is an extreme of low coupling.
Closure of Operations
Most interesting objects end up doing things that can’t be characterized by primitives alone.
Where it fits, define an operation whose return type is the same as the type of its argument(s).
If the implementer has state that is used in the computation, then the implementer is effectively an argument of the operation, so the argument(s) and return value should be of the same type as the implementer. Such an operation is closed under the set of instances of that type.
A closed operation provides a high-level interface without introducing any dependency on other concepts.
Declarative Style of Design
- NOT Declarative Design because of its many pitfalls (see chapter).
Once your design has INTENTION-REVEALING INTERFACES, SIDE- EFFECT-FREE FUNCTIONS, and ASSERTIONS, you are edging into declarative territory. Many of the benefits of declarative design are obtained once you have combinable elements that communicate their meaning, and have characterized or obvious effects, or no observable effects at all.
A supple design can make it possible for the client code to use a declarative style of design.
Discussion
Chapter 11 Applying Analysis Patterns
Quotes
- If you wait until you can make a complete justification for a change, you’ve waited too long.
Discussion
Part 4 Strategic Design
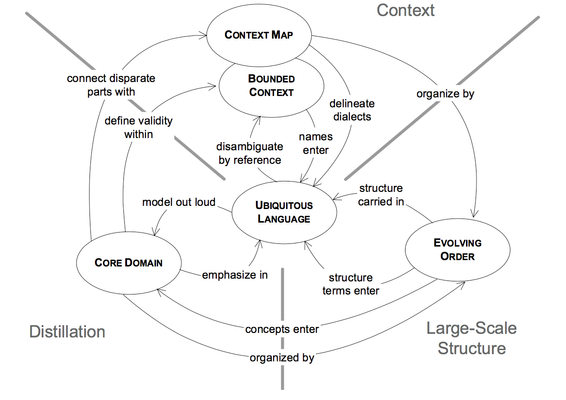
- These three principles, useful separately but particularly powerful taken together, help to produce good designs even in a sprawling system that no one completely understands. Large-scale structure brings consistency to disparate parts to help those parts mesh. Structure and distillation make the complex relationships between parts comprehensible while keeping the big picture in view. BOUNDED CONTEXTS allow work to proceed in different parts without corrupting the model or unintentionally fragmenting it.
- Context, the least obvious of the principles, is actually the most fundamental. A successful model, large or small, has to be logically consistent throughout, without contradictory or overlapping definitions. By explicitly defining a BOUNDED CONTEXT within which a model applies and then, when necessary, defining its relationship with other contexts, the modeler can avoid bastardizing the model.
- Strategic distillation can bring clarity to a large model. And with a clearer view, the design of the CORE DOMAIN can be made more useful.
- Large-scale structure completes the picture. In a very complex model, you may not see the forest for the trees. Distillation helps, by focusing the attention on the core and presenting the other elements in their supporting roles, but the relationships can still be too confusing without an overarching theme, applying some system-wide design elements and patterns.
Chapter 14 Maintaining Model Integrity (1st half)
Quotes
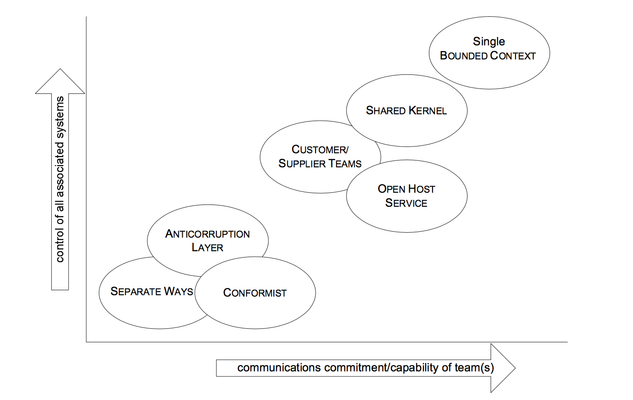
- Total unification of the domain model for a large system will not be feasible or cost-effective.
- It is necessary to allow multiple models to develop in different parts of the system, but we need to make careful choices about which parts of the system will be allowed to diverge and what their relationship to each other will be.
- It all starts with mapping the current terrain of the project. A BOUNDED CONTEXT defines the range of applicability of each model, while a CONTEXT MAP gives a global overview of the project's contexts and the relationships between them. This reduction of ambiguity will, in and of itself, change the way things happen on the project, but it isn't necessarily enough. Once we have a CONTEXT BOUNDED, a process of CONTINUOUS INTEGRATION will keep the model unified.
- Then, starting from this stable situation, we can start to migrate toward more effective strategies for BOUNDING CONTEXTS and relating them, ranging from closely allied contexts with SHARED KERNELS to loosely coupled models that go their SEPARATE WAYS.
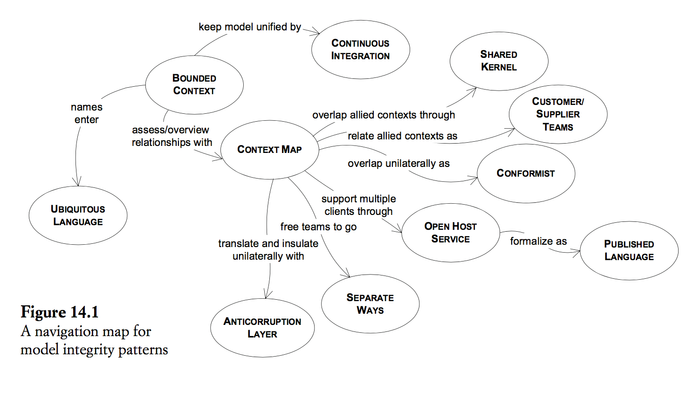
- Explicitly define the context within which a model applies. Explicitly set boundaries in terms of team organization, usage within specific parts of the application, and physical manifestations such as code bases and database schemas. Keep the model strictly consistent within these bounds, but don't be distracted or confused by issues outside.
- Duplication of concepts means that there are two model elements (and attendant implementations) that actually represent the same concept.
False cognates is the case when two people who are using the same term (or implemented object) think they are talking about the same thing, but really are not. - Institute a process of merging all code and other implementation artifacts frequently, with automated tests to flag fragmentation quickly. Relentlessly exercise the UBIQUITOUS LANGUAGE to hammer out a shared view of the model as the concepts evolve in different people's heads.
- Describe the points of contact between the models, outlining explicit translation for any communication and highlighting any sharing. Map the existing terrain. Take up transformations later.
Discussion
Chapter 14 Maintaining Model Integrity (2nd half)
Quotes
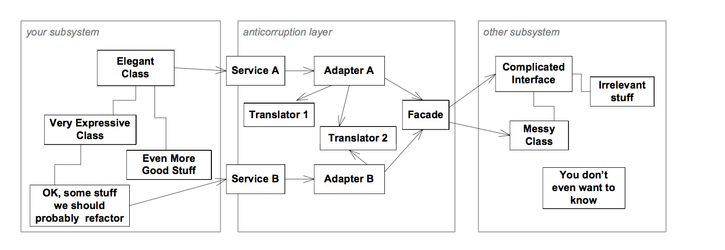
- ANTICORRUPTION LAYER
- Create an isolating layer to provide clients with functionality in terms of their own domain model. The layer talks to the other sys- tem through its existing interface, requiring little or no modification to the other system. Internally, the layer translates in both directions as necessary between the two models.
- One way of organizing the design of the ANTICORRUPTION LAYER is as a combination of FACADES, ADAPTERS, and translators, along with the communication and transport mechanisms usually needed to talk between systems.
- The FACADE belongs in the BOUNDED CONTEXT of the other system.
- SEPARATE WAYS
- Integration is always expensive. Sometimes the benefit is small.
Declare a BOUNDED CONTEXT to have no connection to the others at all, allowing developers to find simple, specialized solutions within this small scope.
The features can still be organized in middleware or the UI layer, but there will be no sharing of logic, and an absolute minimum of data transfer through translation layers—preferably none. - Taking SEPARATE WAYS forecloses some options. Although continuous refactoring can eventually undo any decision, it is hard to merge models that have developed in complete isolation.
- Integration is always expensive. Sometimes the benefit is small.
- OPEN HOST SERVICE
- Define a protocol that gives access to your subsystem as a set of SERVICES. Open the protocol so that all who need to integrate with you can use it. Enhance and expand the protocol to handle new inte- gration requirements, except when a single team has idiosyncratic needs. Then, use a one-off translator to augment the protocol for that special case so that the shared protocol can stay simple and coherent.
- PUBLISHED LANGUAGE
- Use a well-documented shared language that can express the necessary domain information as a common medium of communication, translating as necessary into and out of that language.
- Model Context Strategy
Generally speaking, there is a correspondence of one team per BOUNDED CONTEXT. One team can maintain multiple BOUNDED CONTEXTS, but it is hard (though not impossible) for multiple teams to work on one together.
Discussion
Chapter 15 Distillation
Quotes
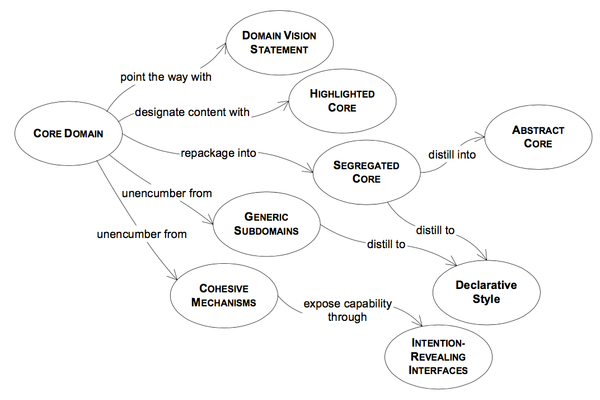
- A simple DOMAIN VISION STATEMENT communicates the basic concepts and their value with a minimum investment. The HIGHLIGHTED CORE can improve communication and help guide decision making—and still requires little or no modification to the design. More aggressive refactoring and repackaging explicitly separate GENERIC SUBDOMAINS, which can then be dealt with individually.
- COHESIVE MECHANISMS can be encapsulated with versatile, communicative, and supple design. Removing these distractions disentangles the CORE. Repackaging a SEGREGATED CORE makes the CORE directly visible, even in the code, and facilitates future work on the CORE model. And most ambitious is the ABSTRACT CORE, which expresses the most fundamental concepts and relationships in a pure form (and requires extensive reorganizing and refactoring of the model).
- Factoring out GENERIC SUBDOMAINS reduces clutter, and COHESIVE MECHANISMS serve to encapsulate complex operations. This leaves behind a more focused model, with fewer distractions that add no particular value to the way users conduct their activities. But you are unlikely ever to find good homes for everything in the domain model that is not CORE. The SEGREGATED CORE takes a direct approach to structurally marking off the CORE DOMAIN.
Core Domain
- Boil the model down. Find the CORE DOMAIN and provide a means of easily distinguishing it from the mass of supporting model and code. Make the CORE small.
- Spend the effort in the CORE to find a deep model and develop a supple design—sufficient to fulfill the vision of the system. Justify investment in any other part by how it supports the distilled CORE.
- But scarce, highly skilled developers tend to gravitate to technical infrastructure or neatly definable domain problems that can be understood without specialized domain knowledge. Apply top talent to the CORE DOMAIN, and recruit accordingly.
- If you need to keep some aspect of your design secret as a competitive advantage, it is the CORE DOMAIN. And whenever a choice has to be made (due to time limitations) between two desirable refactorings, the one that most affects the CORE DOMAIN should be chosen first.
Generic Subdomain
- Identify cohesive subdomains that are not the motivation for your project. Factor out generic models of these subdomains and place them in separate MODULES. Leave no trace of your specialties in them.
- Once they have been separated, give their continuing develop- ment lower priority than the CORE DOMAIN, and avoid assigning your core developers to the tasks (because they will gain little do- main knowledge from them). Also consider off-the-shelf solutions or published models for these GENERIC SUBDOMAINS.
- Options:
- Off-the-shelf
- Published design or model
- Outsourced
- In-house (possibly by temps)
- Though you should seldom design for reusability, you must be strict about keeping within the generic concept.
Domain Vision Statement
- Write a short description (about one page) of the Core Domain and the value it will bring, the “value proposition.”
- A DOMAIN VISION STATEMENT gives the team a shared direction. Some bridge between the high-level STATEMENT and the full detail of the code or model will usually be needed.
Highlighted Core
The CORE DOMAIN must be made easier to see. The mental labor of constantly filtering the model to identify the key parts absorbs concentration better spent on design thinking, and it requires comprehensive knowledge of the model.
Significant structural changes to the code are the ideal way of identifying the CORE DOMAIN, but they are not always practical in the short term. In fact, such major code changes are difficult to un- dertake without the very view the team is lacking.
- 2 options:
- Distillation Document - Write a very brief document (three to seven sparse pages) that describes the CORE DOMAIN and the primary interactions among CORE elements.
Flagged CORE - Flag each element of the CORE DOMAIN within the primary repository of the model, without particularly trying to elucidate its role. Make it effortless for a developer to know what is in or out of the CORE.
Cohesive Mechanisms
Hide complex algorithms in methods with intention-revealing names, separating the “what” from the “how.”
Computations sometimes reach a level of complexity that begins to bloat the design. The conceptual “what” is swamped by the mechanistic “how.”
Partition a conceptually COHESIVE MECHANISM into a separate lightweight framework. Expose the capabilities of the framework with an INTENTION-REVEALING INTERFACE.
Segregated Core
- Refactor the model to separate the CORE concepts from supporting players (including ill-defined ones) and strengthen the cohesion of the CORE while reducing its coupling to other code.
- Factor all generic or supporting elements into other objects and place them into other packages, even if this means refactoring the model in ways that separate highly coupled elements.
- Steps:
1. Identify a CORE subdomain (possibly drawing from the distilla- tion document).
2. Move related classes to a new MODULE, named for the concept that relates them.
3. Refactor code to sever data and functionality that are not directly expressions of the concept. Put the removed aspects into (possibly new) classes in other packages. Try to place them with conceptually related tasks, but don’t waste too much time being perfect. Keep focused on scrubbing the CORE subdomain and making the references from it to other packages explicit and self-explanatory.
4. Refactor the newly SEGREGATED CORE MODULE to make its relationships and interactions simpler and more communicative, and to minimize and clarify its relationships with other MODULES. (This becomes an ongoing refactoring objective.)
5. Repeat with another CORE subdomain until the SEGREGATED CORE is complete.
Abstract Core
- Identify the most fundamental concepts in the model and factor them into distinct classes, abstract classes, or interfaces.
- Design this abstract model so that it expresses most of the interaction between significant components.
- Place this abstract overall model in its own MODULE, while the specialized, detailed implementation classes are left in their own MODULES defined by subdomain.
Choosing Refactoring Targets
- In a pain-driven refactoring, you look to see if the root involves the CORE DOMAIN or the relationship of the CORE to a support- ing element. If it does, you bite the bullet and fix that first.
- When you have the luxury of refactoring freely, you focus first on better factoring of the CORE DOMAIN, on improving the segregation of the CORE, and on purifying supporting subdomains to be GENERIC.
Discussion
Chapter 16 Large Scale Structures
Quotes
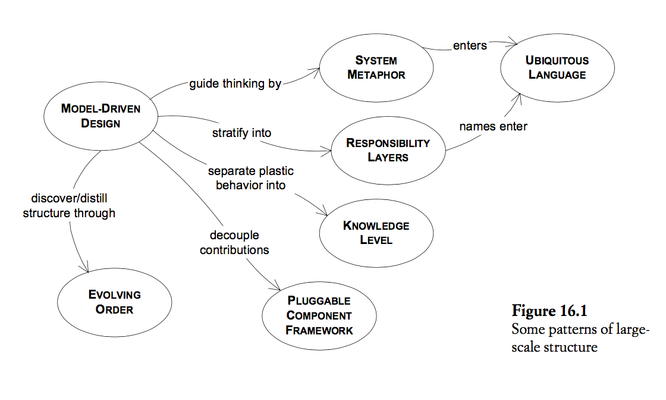
- A “large-scale structure” is a language that lets you discuss and understand the system in broad strokes.
- Devise a pattern of rules or roles and relationships that will span the entire system and that allows some understanding of each part’s place in the whole—even without detailed knowledge of the part’s responsibility.
- In a large system without any overarching principle that allows elements to be interpreted in terms of their role in patterns that span the whole design, developers cannot see the forest for the trees.
One key to keeping the cost down is to keep the structure simple and lightweight. Don’t attempt to be comprehensive.
Evolving Order
- Let this conceptual large-scale structure evolve with the application, possibly changing to a completely different type of structure along the way.
- Don’t overconstrain the detailed design and model decisions that must be made with detailed knowledge.
System Metaphor
When a concrete analogy to the system emerges that captures the imagination of team members and seems to lead thinking in a useful direction, adopt it as a large-scale structure. Organize the design around this metaphor and absorb it into the UBIQUITOUS LANGUAGE.
But because all metaphors are inexact, continually reexamine the metaphor for overextension or inapt- ness, and be ready to drop it if it gets in the way.
Responsibility Layers
- Look at the conceptual dependencies in your model and the varying rates and sources of change of different parts of your domain.
- If you identify natural strata in the domain, cast them as broad abstract responsibilities. These responsibilities should tell a story of the high-level purpose and design of your system.
Knowledge Level
- In an application in which the roles and relationships between ENTITIES vary in different situations, complexity can explode. Neither fully general models nor highly customized ones serve the users’ needs.
- KNOWLEDGE LEVEL untangles things when we need to let some part of the model itself be plastic in the user’s hands yet constrained by a broader set of rules.
- Create a distinct set of objects that can be used to describe and constrain the structure and behavior of the basic model.
- Keep these concerns separate as two “levels,” one very concrete, the other reflecting rules and knowledge that a user or superuser is able to customize.
Like all powerful ideas, REFLECTION and KNOWLEDGE LEVELS can be intoxicating. This pattern should be used sparingly.
Pluggable Component Framework
- Distill an ABSTRACT CORE of interfaces and interactions and create a framework that allows diverse implementations of those interfaces to be freely substituted.
- Likewise, allow any application to use those components, so long as it operates strictly through the interfaces of the ABSTRACT CORE.
Discussion
Chapter 17. Bringing the Strategy Together
Quotes
- ..evolution means that your final structure will not be available at the start, and that means that you will have to refactor to impose it as you go along. This can be expensive and difficult, but it is necessary.
- A large- scale structure can exist within one BOUNDED CONTEXT, or it can cut across many of them and organize the CONTEXT MAP.
When you are tackling strategic design on a project, you need to start from a clear assessment of the current situation.
Draw a CONTEXT MAP. Can you draw a consistent one, or are there ambiguous situations?
Attend to the use of language on the project. Is there a UBIQUI- TOUS LANGUAGE? Is it rich enough to help development?
Understand what is important. Is the CORE DOMAIN identified? Is there a DOMAIN VISION STATEMENT? Can you write one?
Does the technology of the project work for or against a MODEL- DRIVEN DESIGN?
Do the developers on the team have the necessary technical skills?
Are the developers knowledgeable about the domain? Are they interested in the domain?
- An architecture team can act as a peer with various application teams, helping to coordinate and harmonize their large-scale structures as well as BOUNDED CONTEXT boundaries and other cross-team technical issues. To be useful in this, they must have a mind set that emphasizes application development.
- Six essential for strategic decision making
- Decisions must reach the entire team.
- The decision process must absorb feedback.
- The plan must allow for evolution.
- Architecture/infrastructure teams must not siphon off all the best and brightest.
- Strategic design requires minimalism and humility.
- Objects are specialists; developers are generalists.
- Technical frameworks can greatly accelerate application development, including the domain layer, by providing an infrastructure layer that frees the application from implementing basic services, and by helping to isolate the domain from other concerns. But there is a risk that an architecture can interfere with expressive implementations of the domain model and easy change. Evolution, minimalism, and involvement with the application development team can lead to a continuously refined set of services and rules that genuinely help application development without getting in the way.
Don’t write frameworks for dummies.
Advocate a set of principles for all community members to apply to every act of piecemeal growth, so that “organic order” emerges, well adapted to circumstances.