Video Transcripts Design
- Muhammad Rehan (Deactivated)
- Muzaffar Yousaf (Deactivated)
- Nimisha Asthagiri (Deactivated)
Epic
Phase 1.A EDUCATOR-610 - Getting issue details... STATUS
Phase 1.B EDUCATOR-1125 - Getting issue details... STATUS
Phase 1.A COMPLETE
In this phase, our main focus will be to integrate and use 3rdParty transcripts (i.e. Cielo24/3PlayMedia) in edx-platform and the user uploaded transcripts will continue to live in Mongo Content-store. The following is a happy workflow when a user uploads a video from Video Uploads Page within a course.
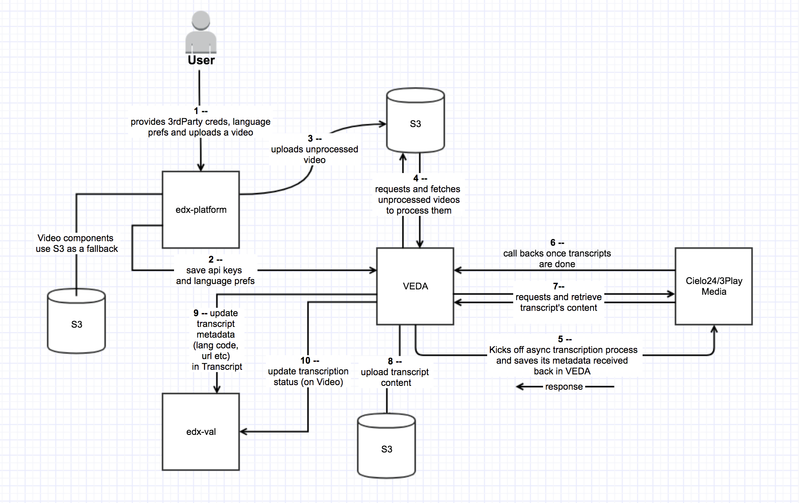
- Users choose between Cielo24/3PlayMedia, enter the 3rdParty api keys and select the languages for (to be auto-generated) transcripts and these 3rdParty api keys will be validated and stored in V
EDAin relation withorganization– (mockups need to be refactored: http://jrpb2q.axshare.com/empty-state.html, http://jrpb2q.axshare.com/transcript-provider-and-language-setting.html). New UX can also be build on Studio dashboard.- On Studio dashboard, we can have "new course" like button which can render "create course" like view but this will be for third party api keys.
- We will be taking organization as an input, check for the user access to that org and retrieve/update the API keys from/to VEDA respectively.
- Following are our main concerns:
- On which roles are we supposed to restrict this to?
- Who can see/edit the api keys?
- User uploads a video. After the VEDA has done processing of the uploaded video, VEDA will make request to Cielo24/3PlayMedia to kick off transcription process with some parameters like: API keys, preferred languages and
callback_url(i.e. for tracking transcription progress). We will get that 3rdParty transcription process's metadata and it will be stored in VEDA. This metadata can be used to ping for the transcripts status ourselves if the callback is not received even after the turnaround time has elapsed – Steps 3, 4, 5. - VEDA receives callback from 3rdParty (Cielo24/3PlayMedia) when transcription process is complete, it then retrieves the transcripts' content for all the preferred languages from Cielo24/3PlayMedia and uploads it to S3 and sends the metadata (i.e. language code, format, url etc) to
edx-val– Steps 6, 7, 8, 9. - VEDA updates the
Transcriptwith retrieved metadata (i.e. language code, format, url etc) and updates the transcription status onVideothroughedx-val– Steps 9, 10.
Database Models
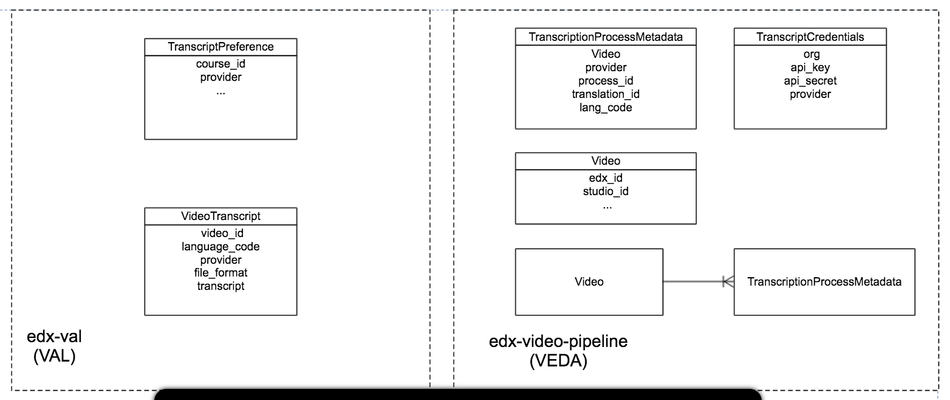
Entity Relationship Diagram for phase 1 is shown as follow:
Video Transcript Status
A char field will be added to the current Video model in edx-val.
transcription_status: this will be status of transcription process going on the 3rdParties( i.e. 3PlayMedia/Cielo24).This is going to have one-time performance impact as of the fully rewrite ofedxval__videotable – https://docs.djangoproject.com/en/1.8/topics/migrations/#mysql
Transcript status would be updated in existing status field that lies in Video Model. There will be two more transcript statuses that we will be taking care of:
- TRANSCRIPTION_IN_PROGRESS
- TRANSCRIPTION_READY
VideoTranscript
This is where transcripts data will live.
video_id: It could be edx_video_id or id from from external sources. e.g. external youtube idlanguage_code: It will be language codeprovider: 3playmedia / cielo24 / custom uploadedformat: It will be transcript's format srt/sjsontranscript(CustomizableFileField): It will be transcript name from S3 (url will be generated at run time)
WARNING: Changing transcript for a video in one course will change it for entire edX courses having the same video.
TranscriptPreference
This is where course specific preferences would be saved.
course_id
providercielo24_fidelitycielo24_turnaroundthree_play_turnaroundpreferred_languages
TranscriptCredentials
This is where org-wide settings for 3rdParty Credentials will live.
org: An org, one org will have only one such preferenceapi_key: API Key for 3play/Cielo24api_secret: API secret for 3Playpreferred_langs: json field to contain list of preferred language codesprovider: Transcription Providers (i.e. 3play/Cielo24)
TranscriptionProcessMetadata
Metadata for kicked off transcription processes will be saved in this model. This metadata may be required when we refetch processed transcripts from 3rd parties. It can also be used when we want to ping the 3rd parties to fetch transcription process status – i.e. in case when we do not receive call and the given turnaround time has elapsed. Every transcription process will be aware of the api keys it need to communicate to the third parties.
edx_id:Videowill haveOneToOnerelationship withTranscriptionProcessMetadataprocess_id: Cielo24/3PlayMedia assigned identifierprovider: 3rdParty source name (i.e. 3play/Cielo24)lang_code: target transcription language
Studio & VEDA
Organizational members will be able to update Transcript Provider settings from Studio Dashboard (Need new UX though)Members select the organization and then Add/Edit Transcript Provider settings in VEDA – There will be request to VEDA to Add/Edit the settings.- In this phase the credentials will be saved via VEDA Django admin
- Course specific preferences will have their UX on studio Video Uploads Page
VEDA & VAL
In video ingest phase, when the cataloging is done and encoding jobs are queued (veda_file_ingest.py#L120-L133), – (reason for strikethrough: At this point, we cannot tell whether encoding will be a success or a failure and in case of failure there is no point of having transcripts). In video delivery phase (video_worker/__init__.py#L183-L186), VEDA starts the transcription processing for a video. VEDA retrievesThirdPartyTranscriptionPrefsfor the given org extracted fromCoursemodel as everyVideothat undergo processing in VEDA, has an associatedCourseas well. VEDA starts the transcription process and stores its metadata for further tracking/communication.- For a video, once a transcription process is in progress, changing the third party settings may invalidate any in progress transcription processes. The video uploads who are having their transcription process started will be effected by change in preference (e.g. if an org changes the provider from Cielo24 to 3PlayMedia).
- Once transcription is done VEDA will receive transcripts from 3Play/Cielo24, it will send them to S3, update transcription status and transcript metadata in
edx-val.
Video Component & Read
- At this stage we will have two data storages for transcript data which are
- contentstore (old)
- s3 (new)
- In this phase any transcript upload made from video component/studio will be stored to the contentstore and any transcript upload made from video pipeline will be stored via the new S3 infrastructure. Since we have two data stores at this stage, we've to incorporate both while reading the content. To handle this situation, we'll treat contentstore as first class storage for any lookup/read and will use S3 storage as fallback, if requested data is not found in contentstore.
- We're using transcript data from different places given below:
- Author view for view component editor & download
- Student view for video component & their downloads
- Language menus / Translations
- Using them as captions to show on player
- Mobile API's are also using transcripts
- Video Bumper (Pending yet)
- For video components which have multiple video sources, e.g internal & external, we'll show unique transcripts associated with given sources. For example, if a video component have external YT link with English & Chinese transcripts and 2nd source is from VAL with English and German translation, we'll show English, German and Chineese. These transcripts could be from both data stores.
Course Export/Import & Re-run
- We'll take care of transcripts for course import/export just like video images without affecting data stored in contentstore.
- We've not touched course re-runs, since transcripts are video specific not course.
Phase 1.B IN PROGRESS
In Phase 1.A, we decided to use video pipeline's Django admin to take 3rd party credentials as input which is not ideal since course team won't have access to the pipeline's admin. This phase solely focus on addressing that concern which is not addressed in phase 1.A.
Third Party Credentials
- In this phase we'll incorporate new UX on Video Uploads to take 3rd party credentials as input from course teams
- These credentials will be organization specific and all courses under particular org will use these for trnascription process
- Third party credentials will be stored in same data model TranscriptCredentials that we defined in 1.A
- There should be a communication between platform and video-pipeline to store these credentials in pipeline
- There is JWT Authentication for these server to server requests/communication.
- We won't be storing credentials in platform/VAL but as cache, we'll store credentials state in VAL to avoid the same credentials at multiple place(s)
- We won't show the saved credentials to reduce the reads but coure teams can update them anytime without seeing the existing ones
- The credentials should be encrypted as per requirement of edX legal department.
- We will be using
django-fernet-fields(that is built on Fernet) as recommeded in Storing (3rd party) Secrets. - For fernet keys rotation, here is our Fernet Keys Rotation Policy.
Database Model
OrganizationTranscriptCredentialsState – VAL
- org – This will be short organization name.
- provider – Cielo or 3playMedia
- exists – True or False
In order to release this phase, we are trying to setup video pipeline via ansible just like other IDAs. This will also add other things like Splunk, New Relic which will make things easier to debug and help us in syncing up the testing + production environtment. This document is not covering up those details.
Phase 2 IN PROGRESS
This has given us opportunity to reduce the complexity in transcription flow in case of those video components that do not use VEDA produced videos. The strike-through lines are to indicate what was decided previously and to understand better where we are going now.
In this phase, our main focus will be to implement S3 backend for the video transcripts module make video component use edxval for video transcripts. Video transcripts storage is abstracted and it can be configured for edxval (for example, as an S3 storage). The following will be the workflow when a user uploads a video from Video Uploads Page within a course. Following is transcription flow with S3 storage:
![]()
- Video transcripts uploaded from components will go to S3 and their metadata will stays in
VideoTranscriptdata model inedx-val. S3 will be used preferably for transcription upload and retrieval over the mongo contentstore. So, contentstore will continue to work but as a fallback unless all the transcripts data is migrated from contentstore to S3.
Following is the transcript authoring flow from a Video Component in general: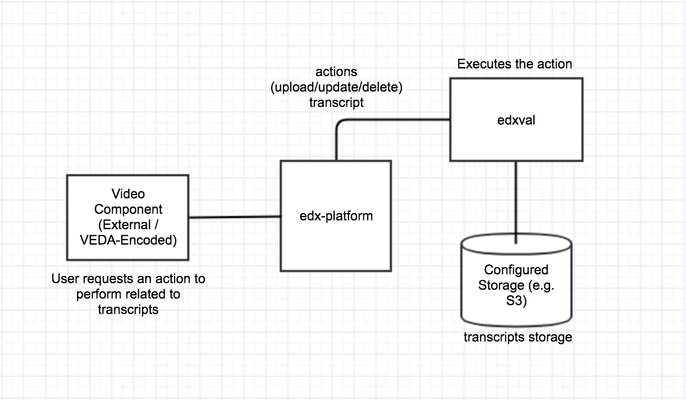
Data Models Update
VideoTranscript data model will have an explicit foriegn key relationship with the Video.
Actions affecting the Transcripts
Following are the actions that will effect transcripts on a video component.
>Upload transcript
Transcript flow will slightly vary depending on the type of the video.
1. VEDA Encoded Video Components
These are the video components that use VEDA produced encodings for playback.
New Transcript
Author uploads a transcript from the video component, transcript is uploaded to S3 and the metadata is stored in VideoTranscript for that Video. This transcript metadata will also be set on the video component.
Update Transcript
If a language's transcript is already there for a video, then uploading newer one for the same language will overwrite the existing transcript (metadata + content).
Delete Transcript
Removing transcript from the video component will delete it for an edx_video_id. It will be deleted from VideoTranscript as well as from S3. This cannot be rolled back. Before this action to take place, we will show a conformation dialog to user to avoid mishaps (for example, user did not pay attention while deleting a transcript). This action will be logged in order to be able to troubleshoot it.
2. External Video Components
These are the video components which do not use VEDA produced encodings rather they consume the external video URLs for playback.
The given transcript will be uploaded on S3 and the metadata will be saved inTranscriptwithexternal_video_idand will also be set on the video component.Theexternal_video_idwill be the ID extracted from external video source URLs (i.e. from YT / HLS / MP4 / Webm)Transcripts will be created (or updated if already there) for all the compoenet's external video source URLs (i.e. YT / HLS / MP4 / Webm)This assumes that a video component may have multiple external video sources (i.e. video URLs) but all having the same video content / footage.Transcripts will continue to show up on video component if any of the external video sources (i.e. video URLs) is removed as we have ceated transcripts for all the sources.
New Transcript
Author uploads a transcript from the video component, video component requests VAL to upload the transcript.
- VAL generates an
edx_video_idand create a Video record with it. - VAL creates
VideoTranscriptrecord with thatVideorecord and tanscript metadata while the content is uploaded to configured storage (for example, S3). - Finally, VAL returns the
edx_video_idand it is backpopulated into the Video Component.
We will use status field from Video data model to indicate the origin for these auto-generated videos and status's value will be "External" for such videos.
Update Transcript
This will remain same as for the "VEDA Encoded Video Components"
Delete Transcript
This will also remain same as for the "VEDA Encoded Video Components"
>Update Video Source(s)
This revolves around updating playback source in a video component.
Current behaviour with Contentstore
Currently, when a new video (i.e. via edx_video_id/external urls) is added on video component, then the previously associated transcripts will remain associated (i.e. transcripts will be renamed according to the new video source in the contentstore). This is also overwriting any transcript in contentstore which is having the same name as this newly added video source, as a result, any other video component which is also using it, will now show that overwritten transcript.
We have two ways depending on the VAL/non-VAL video components for the Video Components having edx_video_id.
VEDA Encoded Video Components
We can either
- Just show on component whatever transcripts are already associated with the newly added
edx_video_idinVideoTranscriptdata model. If no transcript is associated, then show none. - Following the current approach, copy the old
edx_video_idtranscripts and use them for newedx_video_idon the video component – i.e. this will update transcripts for thisedx_video_idinTranscriptmodel.(rejected!)
It has been decided to go with option 1. More details on EDUCATOR-1760 - Getting issue details... STATUS .
External Video Components
Transcripts will not come along on editing external URL(s) because transcripts are Video-specific, there has to be an edx_video_id and all the associated transcripts will show up on the video component.
We can either
Just show on component whatever transcripts are already associated with the newly added external video source(s). If no transcript is associated with this source, then show none.Following the current approach, copy the current transcripts from a video component and rename them for the newly added external source – i.e. this will update transcripts for the newly added source inTranscriptmodel.
Deprecate "Default Timed Transcript" aka sub & "Translations" aka transcripts
"Default Timed Transcript" aka sub
Currently, when we upload an english transcript from a video component, it is saved into the contentstore for each Video URL of that component, and the “Default Timed Transcript” gets filled with an identifier extracted from one of its Video URLs (whichever has got the higher playback priority) – the extracted identifier referred to as sub_id and it is used to query the transcript from contentstore. So, the purpose of “Default Timed Transcript” is to keep track of which english transcript is linked to the prioritized Video URL.
"Translations" aka transcripts
As of today, all the transcripts uploaded through Video Component's Advanced Tab are directly associated to that video component and the uploaded content lives in Contentstore. So, the transcripts uploaded in this case, are component-specific and transcripts implements this. It is a dict xField that is used to keep track of the non-english transcripts (i.e. filename against language code).
Reason
We will be moving towards associating transcripts to edx_video_id and the metadata will be in the VideoTranscript data model (regardless english transcripts or non-english transcripts). Hence, there will be no need for these fields which were previously used to keep transcript metadata on a video component. Not to miss, transcripts field is tightly coupled with Video Component's Advanced Settings currently, we will need to inject an alternate UI for authors to be able to manage transcripts once we deprecate it.
Note:
After this phase, transcripts will be preferably checked in S3 but if they are not found there, content-store will serve as a fallback until all the data is migrated to S3. After this phase, transcripts will only be utilized from the VAL configured storage(e.g. S3) and contentstore will not be used, not even as a fallback. We will need to migrate the contentstore transcripts into the S3 before we roll this phase out. We will be writing more about transcripts migration on Migration from contentstore to s3.
Course Import/Export (Transcript S3 URLs)
Transcript Export/Import
Transcripts Import/Export that includes transcript S3 URLs. This section is deprecated as per decision to include transcript content with course OLX – EDUCATOR-2233 - Getting issue details... STATUS .
Please have a look at the comments section:
Regarding export/import, please see Transcript import/export scenarios. At this time, we do not need to export the Transcript content along with the course's OLX. The behavior should be the same as it is today for export/import of VAL-produced videos. That is, only the VAL metadata needs to be exported with the course. The assets (transcript content and video content) do not need to be exported along with the course.
The plan is to keep transcript metadata with the Course's OLX on exporting the course. On importing the course, we will not allow overwriting(or creation) any of the transcripts if the related video is already present in Video data model.
Export
On a course export, video transcripts metadata including the URLs to the transcript files, will be exported with the Course. The original transcript files will not be exported with Course OLX and they will continue to live in the configured storage (for example, S3, local or other).
Import
On a course import,
- For existing videos, transcripts will not be updated in VAL, this is to avoid overwriting the transcripts for an existing Video (this is happening for video encodings) – suggested here.
- For the other videos, transcripts will created through the exported metadata, and transcript content will be fetched (via exported transcript URL) and stored in instance's configured storage.
Course Import/Export (Transcripts in OLX)
Transcripts Export/Import
Transcripts Export/Import including transcript content in Course OLX.
| Abbreviation | Definition |
|---|---|
| OLX | Open Learning XML |
| DS | Django Storages |
Transcript files will be exported with the course's OLX instead of their S3 URLs. Course OLX must not be changed. Currently, contentstore transcript files are exported to(or imported from) /static/ directory in course OLX and these files are referenced via sub and transcript fields from the video component or its XML. In future, the DS transcript files will also be exported to the same /static/ directory in Course's OLX. The export/import scenarios can be seen as follow:
![]()
(From Nimisha Asthagiri (Deactivated))
We have tried to cover these scenarios in our initial proposal on transcript content portablity in export/import.
Export
When a video component is exported, transcripts associated to that video goes to course OLX’s /static/ directory while the metadata tracking those transcript files stays in video component’s XML (as separate <transcripts/> tags).
Currently, on a course import, all the file under
/static/are dumped back to the contentstore for that course. Consequently, DS transcript files will also be dumped into the contentstore. Can this be taken as future optimization?
Backward Compatibility
New Transcripts: These refers to the Transcripts that are in the django-storages (e.g. S3 for edx.org)
Why is this required?
Exporting a course from edx.org and import it into an older open edX instance(<= ginkgo) do not import the New Transcripts. This is because "open-release/ginkgo.master" does not have the feature (i.e. "Transcripts Phase 2 Deprecate Contentstore") available. So, we need to be backward compatible unless Ginkgo is deprecated and the new open-release having the feature is official.
For the backward compatibility, New Transcripts will be saved into the /static/ directory with old naming standards. Following are the technical implementation details:
- For new `en` transcripts:
- A file, having New Transcript content, will be created in /static/ directory with the name in old format i.e.
subs_<sub_id>.srt.sjson sub_idwill come either fromvideo.subor video source ids (i.e.youtube_id_1_0,html5_ids)- if
sub_iddoes not come fromvideo.subthen it will be updated onvideo.subin the xml, so that, it becomes usable/reachable after importing this video component. - For new transcripts other than `en`:
- if
video.transcriptsdoes not have record for the corresponding New Transcript’s language code: - A file, having new transcript content, will be created in /static/ directory with the name in old format i.e.
<lang_code>_subs_<subs_id>.srt.sjson. sub_idwill come either fromvideo.subor video source ids (i.e.youtube_id_1_0,html5_ids)- The filename (i.e.
<lang_code>_subs_<subs_id>.srt.sjson) will be set onvideo.transcriptsin the xml. - if
video.transcriptshas filename present for the corresponding New Transcript’s language code: - A file, having New Transcript content, will be created in /static/ directory with the filename found in
video.transcripts.
Import
When a video component is imported as a part of course import, the flow will be as follow:
- "Old" transcripts' references (`sub` and `transcripts` fields) are retrieved from the video component XML, these references are checked in OLX’s
/static/directory for the transcript file matches. The transcript files found are imported to the edxval’s configured DS. - For external video components, video ID is generated, transcripts are associated to the generated video ID, and it is populated back to the component as
edx_video_id. - For VEDA-produced video components, if video ID is already present in edxval then, do not overwrite any video transcripts.
- "New" transcripts metadata tags (from video component’s XML) are used to import transcript files from course OLX
/static/directory to edxval’s configured DS. - "No transcript overwrite on import" applies here as well, for example, If video ID is already present in edxval then do not overwrite any video transcripts.
Phase Rollout Plan
- This phase will stop the transcripts upload to the contentstore and new transcripts will start going to edxval's configured storage (e.g. S3).
- Since the transcripts are not migrated yet, there will be an interface which will retrieve transcripts from the contentstore if it cannot find them in S3.
- The transcript retrieval above will be behind a course waffle flag (e.g.
isContentstoreDeprecate) which will be set to true when a course is successfully migrated and the interface will never retrieve transcripts from contentstore for the corresponding course.
- The transcript retrieval above will be behind a course waffle flag (e.g.
- Since the transcripts are not migrated yet, there will be an interface which will retrieve transcripts from the contentstore if it cannot find them in S3.
- When the newly uploaded transcripts are not going to the contentstore, the migration phase can be executed to migrate the existing contentstore transcripts into S3.
- More details on transcripts migration phase can be found on Migration from contentstore to s3.
Access S3 Transcripts from Open edX instances
A course can be exported from edx-platform studio instance to some open edx instance. Transcript will also get exported with the video component in a course export and when this course is imported in an open edx instance Transcript will be imported with a video component as well. We may not want an Open edX instance to serve transcripts using our cloud-front distribution. So, it will also need to enable CORS for accessing the transcripts but only from allowed instances.